-
Journald Crash
昨天和芽哥一起查了一个 ETCD 切主的问题,挺有意思的,记录一下。
最终查明了根因,是使用 filebeat 采集 Journal 日志,引发 journald flush,导致高磁盘 IO,进而导致 ETCD 切主。
-
Docker Proxy
Proxy effect in dockerd(docker daemon) is different from that in docker cli.
Proxy setting in dockerd acts when dealing with registry, such as
docker pull push login.Command in dockerfile when doing
docker buildanddocker runuse proxy setting in docker cli (NOT automatically in environment way, see details below). -
Docker Push 500 Path Not Found
最近几天 Harbor 出现比较多的 500 错误,引发告警。排查一下原因。
registry.log 里面的错误日志
Apr 6 11:46:40 172.25.0.1 registry[3915]: time=”2022-04-06T03:46:40.800755496Z” level=error msg=”response completed with error” auth.user.name=”harbor_registry_user” err.code=unknown err.detail=”s3aws: Path not found: /docker/registry/v2/repositories/gitlab-ci/100017681/_uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370/data” err.message=”unknown error” go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri=”/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D” http.request.useragent=”docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce (linux))” http.response.contenttype=”application/json; charset=utf-8” http.response.duration=2.255332326s http.response.status=500 http.response.written=203 vars.name=”gitlab-ci/100017681” vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370
看代码梳理一下 docker push 的流程
Docker Cli 这边 upload blob 的流程是:
- docker cli 调用 POST /v2/
/blobs/uploads/ 获取 uuid - docker cli 调用 PATCH /v2/
/blobs/uploads/
着重翻代码看一下 Registry 这边对这两个操作的对应的处理流程:
- buh.StartBlobUpload
- 调用到 s3.Writer(ctx context.Context, path string, append bool)。append = false
- 调用到 d.S3.CreateMultipartUpload
- 生成一个 UUID
- 调用 S3 接口 Create 一个 Object。
POST /{Bucket}/{Key+}?uploads - TLDR: 在 S3 创建一个对象,然后生成一个 UUID 并返回给 Client。
- buh.PatchBlobData
- 调用到 bub.ResumeBlobUpload
- 调用到 blobs.Resume(buh, buh.UUID)
- 调用到 s3.Writer(ctx context.Context, path string, append bool)。append = true
for _, multi := range d.S3.ListMultipartUploads{}。遍历失败,返回 storagedriver.PathNotFoundError- TLDR: 按 UUID 找到对应的对象,然后写数据进去。
流程看起来问题不大,先创建对象,然后写数据。问题出在,第一步里面调用的 S3 创建对象是异步处理的,第二步请求来的时候,对象还没有创建好。
日志验证
通过看 S3 的 Harbor 的日志,基本上可以确定这个问题了。但还没有在代码层面看到异步的证据。应该是需要看 S3 SDK,一时看不动了。
我们拿一个出错的请求,来通过日志确认一下。
请求在 registry.log 里面的日志如下:
Apr 6 11:46:38 172.25.0.1 registry[3915]: time="2022-04-06T03:46:38.546533285Z" level=debug msg="authorizing request" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370 Apr 6 11:46:38 172.25.0.1 registry[3915]: time="2022-04-06T03:46:38.549190549Z" level=info msg="authorized request" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370 Apr 6 11:46:38 172.25.0.1 registry[3915]: time="2022-04-06T03:46:38.549281495Z" level=debug msg="(*linkedBlobStore).Resume" auth.user.name="harbor_registry_user" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370 Apr 6 11:46:38 172.25.0.1 registry[3915]: time="2022-04-06T03:46:38.552098655Z" level=debug msg="s3aws.GetContent("/docker/registry/v2/repositories/gitlab-ci/100017681/_uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370/startedat")" auth.user.name="harbor_registry_user" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" trace.duration=2.760534ms trace.file="/go/src/github.com/docker/distribution/registry/storage/driver/base/base.go" trace.func="github.com/docker/distribution/registry/storage/driver/base.(*Base).GetContent" trace.id=aa22d5f1-24db-4d80-8867-bec6b3daadc2 trace.line=95 vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370 Apr 6 11:46:40 172.25.0.1 registry[3915]: time="2022-04-06T03:46:40.800564701Z" level=debug msg="s3aws.Writer("/docker/registry/v2/repositories/gitlab-ci/100017681/_uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370/data", true)" auth.user.name="harbor_registry_user" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" trace.duration=2.248339896s trace.file="/go/src/github.com/docker/distribution/registry/storage/driver/base/base.go" trace.func="github.com/docker/distribution/registry/storage/driver/base.(*Base).Writer" trace.id=8dfdaa69-9ace-4c3e-86cc-ef9c330b5106 trace.line=142 vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370 Apr 6 11:46:40 172.25.0.1 registry[3915]: time="2022-04-06T03:46:40.800637996Z" level=error msg="error resolving upload: s3aws: Path not found: /docker/registry/v2/repositories/gitlab-ci/100017681/_uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370/data" auth.user.name="harbor_registry_user" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370 Apr 6 11:46:40 172.25.0.1 registry[3915]: time="2022-04-06T03:46:40.800755496Z" level=error msg="response completed with error" auth.user.name="harbor_registry_user" err.code=unknown err.detail="s3aws: Path not found: /docker/registry/v2/repositories/gitlab-ci/100017681/_uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370/data" err.message="unknown error" go.version=go1.15.6 http.request.host=hub.xxx.com http.request.id=5bfcac34-34fa-4a05-ae52-b3fbb3714de2 http.request.method=PATCH http.request.remoteaddr=10.109.6.219 http.request.uri="/v2/gitlab-ci/100017681/blobs/uploads/9ac3ea44-cbb6-4a1b-8048-6e59767c7370?_state=YmUOEA6F6k5OZsTu9CyQfl5CRNqlVEvx7XKgf_BVqLl7Ik5hbWUiOiJnaXRsYWItY2kvMTAwMDE3NjgxIiwiVVVJRCI6IjlhYzNlYTQ0LWNiYjYtNGExYi04MDQ4LTZlNTk3NjdjNzM3MCIsIk9mZnNldCI6MCwiU3RhcnRlZEF0IjoiMjAyMi0wNC0wNlQwMzo0NjozNi4yNTQ4MzA2MzRaIn0%3D" http.request.useragent="docker/17.09.0-ce go/go1.8.3 git-commit/afdb6d4 kernel/4.19.118-1.el7.centos.x86_64 os/linux arch/amd64 UpstreamClient(Docker-Client/17.09.0-ce \(linux\))" http.response.contenttype="application/json; charset=utf-8" http.response.duration=2.255332326s http.response.status=500 http.response.written=203 vars.name="gitlab-ci/100017681" vars.uuid=9ac3ea44-cbb6-4a1b-8048-6e59767c7370对应的 Registry Access log 如下:
第一步请求:
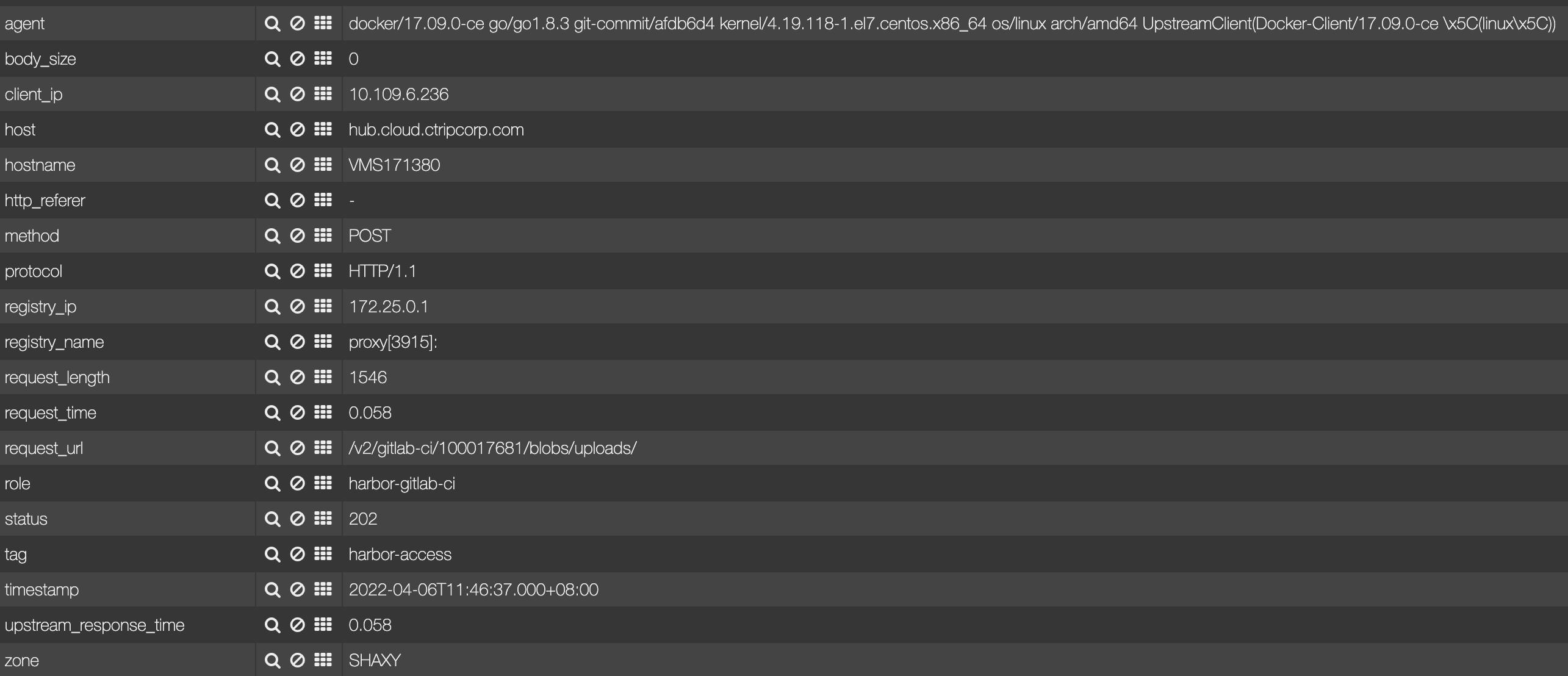
第二步请求:
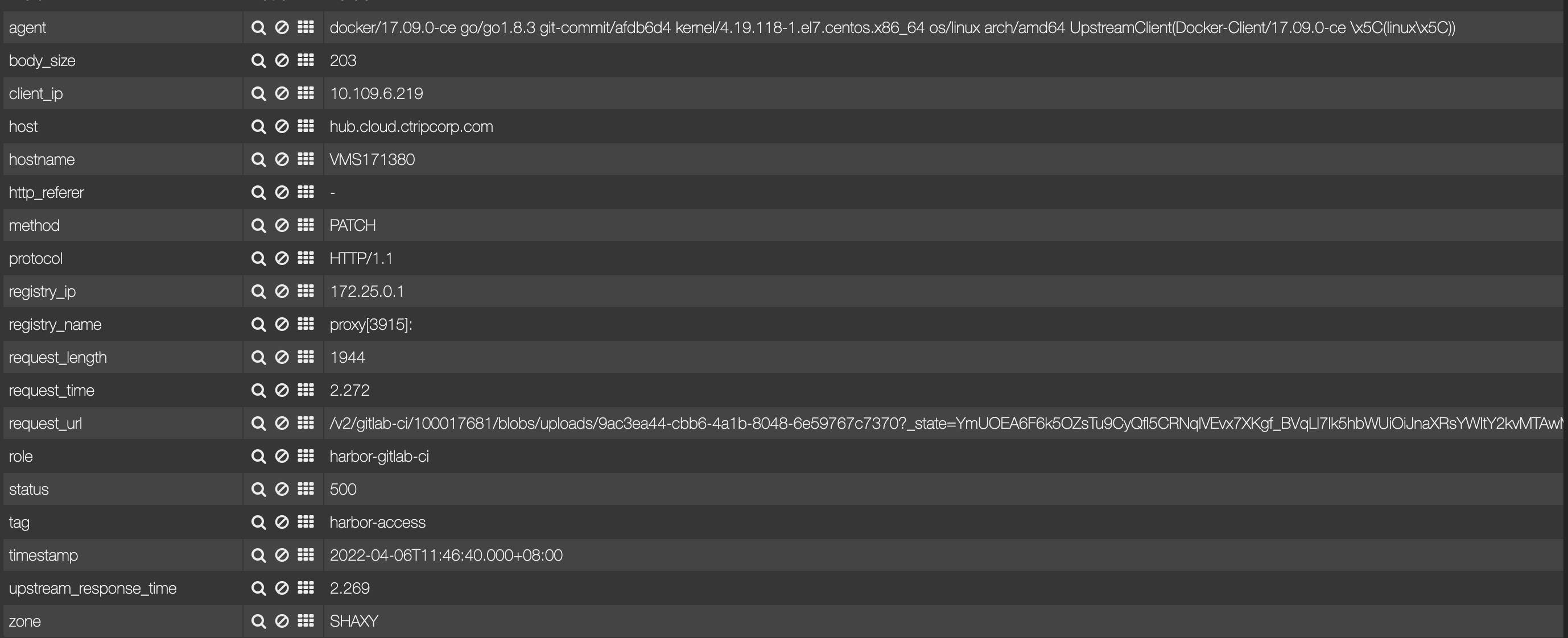
第一步中 对应的 S3 的 Access 日志如下:
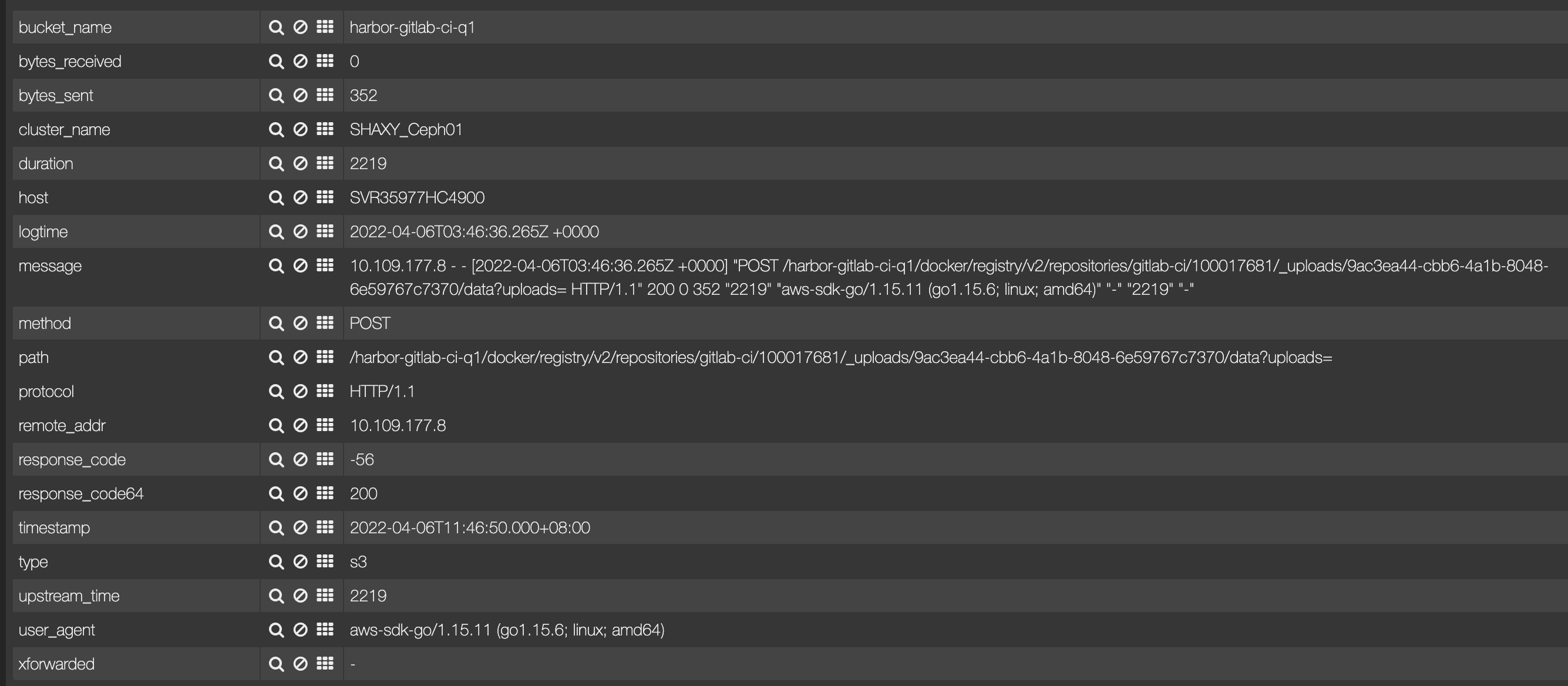
可以看到两点:
- 请求 2.2 秒才返回,但 Registry 这边 58 毫秒就返回了。所以怀疑是异步。
- S3 请求处理完的时候,Client 这边的第二步已经执行了,导致 PathNotFoundError。
- docker cli 调用 POST /v2/
-
harbor 中 oidc 认证的一些笔记
使用版本是 harbor v2.2.0。本文只是记录了一些 OIDC 认证相关的东西。需要事先了解一些 SSO 知识和 Docker HTTP V2 API
Harbor Core 组件分两个比较独立的功能,一个是提供 Token 服务,一个是反向代理后面的 Registry 。两者都有和 OIDC 打交道的地方。
Harbor 中使用 OIDC 的地方,大的来说有两个。一个是 Web 页面登陆的时候,一个是 docker login/pull/push 时的身份认证。
数据库里面和 OIDC 相关的一个重要表是 oidc_user,里面有两个重要的列,一个 secret,也就是密码,另外一个是 token,用来做验证(比密码更多一层安全?)。
-
cgroup v2 学习笔记简记
参考资料
启用 cgroup-v2
测试系统环境:
# cat /etc/centos-release CentOS Linux release 7.6.1810 (Core) # systemctl --version systemd 219 +PAM +AUDIT +SELINUX +IMA -APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 -SECCOMP +BLKID +ELFUTILS +KMOD +IDN # uname -a Linux VMS171583 5.10.56-trip20211224.el7.centos.x86_64 #1 SMP Fri Dec 24 02:11:17 EST 2021 x86_64 x86_64 x86_64 GNU/Linux如果控制器(cpu,memory 等)已经绑定在 cgroup v1,那就没办法再绑定到 cgroup v2 了。
systemd 又是 pid 1 进程,所以第一步需要让 systemd 使用 cgroup v2。
grubby --update-kernel=ALL --args=systemd.unified_cgroup_hierarchy=1使用上面命令添加内核启动参数,然后重启,可以让 systemd 使用 cgroup v2。
但我的测试环境中,这个版本的 systemd 还不支持 cgroup v2,所以添加了这个参数也没用。https://github.com/systemd/systemd/issues/19760
所以需要强制关闭 cgroup v1:
grubby --update-kernel=ALL --args=cgroup_no_v1=all重启之后,
mount | grep cgroup可以看到 cgroup v1 的 mount 已经没有了。(可能 systemd 不能再对服务做资源控制了?未验证)mount cgroup v2
# mkdir /tmp/abcd # mount -t cgroup2 nodev /tmp/abcd/ # mount | grep cgroup2 nodev on /tmp/abcd type cgroup2 (rw,relatime)成功 mount cgroup v2 了,接下来就能使用 v2 做资源控制了。
开启 CPU 限制
看一下 v2 里面有哪些可用的控制器
# cat cgroup.controllers cpuset cpu io memory hugetlb pids创建一个 child cgroup
# cd /tmp/abcd [root@VMS171583 abcd]# mkdir t开启 CPU 控制器
cd /tmp/abcd [root@VMS171583 abcd]# ll t total 0 -r--r--r-- 1 root root 0 Mar 22 15:10 cgroup.controllers -r--r--r-- 1 root root 0 Mar 22 15:10 cgroup.events -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.freeze -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.max.depth -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.max.descendants -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.procs -r--r--r-- 1 root root 0 Mar 22 15:10 cgroup.stat -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.subtree_control -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.threads -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.type -r--r--r-- 1 root root 0 Mar 22 15:10 cpu.stat echo "+cpu" > cgroup.subtree_control [root@VMS171583 abcd]# ll t total 0 -r--r--r-- 1 root root 0 Mar 22 15:10 cgroup.controllers -r--r--r-- 1 root root 0 Mar 22 15:10 cgroup.events -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.freeze -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.max.depth -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.max.descendants -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.procs -r--r--r-- 1 root root 0 Mar 22 15:10 cgroup.stat -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.subtree_control -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.threads -rw-r--r-- 1 root root 0 Mar 22 15:10 cgroup.type -rw-r--r-- 1 root root 0 Mar 22 15:14 cpu.max -r--r--r-- 1 root root 0 Mar 22 15:10 cpu.stat -rw-r--r-- 1 root root 0 Mar 22 15:14 cpu.weight -rw-r--r-- 1 root root 0 Mar 22 15:14 cpu.weight.nice可以看到 CPU 的接口文件就自动创建好了。
更改一下 CPU 资源控制的参数:
cd /tmp/abcd/t echo 20000 100000 > cpu.max跑一个 Python 死循环脚本,可以看到 CPU 使用率100%。
cd /tmp/abcd/t echo $pythonPID > cgroup.procs可以看到 python 进程的 CPU 使用率被限制到 20% 了。
-
Docker Push 503
记一下刚刚发生的 Docker Push 一直重试,最后报错
received unexpected HTTP status: 503 Service Unavailable的事。 -
dockerd 里面使用 lz4 解压缩测试小结
线上 dockerd 版本: Docker version 19.03.12, build 48a66213fe
实验使用的 dockerd 版本:v20.10.9
目的
为了加速容器的启动,docker pull 做为其中的一环,调研一下如何加速 docker pull。
局域网环境问题下,docker pull 里面的解压的时间占了大头。Lz4 的解压速度比当前 Docker 默认的 gzip 要快不少,我们就在 Docker 里面实际测下看效果。
-
Harbor v2.2.0 中 Sweep 引发的两个问题
在说这些问题之前,先说一下 Harbor 里面触发镜像复制任务(其他任务类似)的大概流程。
-
Put Manifest 接口已经是 Docker Push 的最后一步了,里面会生成 Event,并做 Publish。至于需要 Publish 到哪里去,是https://github.com/goharbor/harbor/blob/release-2.4.0/src/pkg/notifier/notifier.go 里面注册的。
-
controller/replication/controller:Start 里面创建一个 Execution (注意,这里会创建 Sweep Goroutine)
-
开一个 Goroutine ,创建 Tasks (一个 Execution 可能对应多个 Tasks)
-
Task 里面提交 Job,
POST /api/v1/jobs -
Core 组件里面收到这个请求,调用 LauchJob,会任务 Enqueue 到 Redis 里面注册的。
以上都是 Core 里面做的。
接下来 Jobservice 组件收到这个 Job,开始处理。并在任务成功或者失败时,回调一下配置在 Job 里面的 StatusHook。
-
-
我们的 Habror 灾备架构
介绍一下背景,我们使用 harbor 做镜像仓库服务,后端存储使用 Ceph。
现在 1 需要做两机房的灾备, 2 Ceph 还没有两机房的集群能力。
-
记一个 Harbor 中的小问题 -- get-manifest header-content-type 变化
起因
一个同事 使用 Ruby 调用 harbor
GET /v2/<name>/manifests/<reference>接口,开始的时候没有问题。后来,因为我们 harbor 架构的问题,对 harbor 代码做了一个小的改造。导致同事那边 Ruby 拿到的结果不认为是 Json,而是一个 String,需要再次 Json 解析一次。
同事看起来,认为是 header 里面的 content-type 变了导致的。需要我们查明一下原因。