-
搭建Kafka集群时, 对ZooKeeper认证与权限控制
废话写在最前
-
公司需要部署一套kafka, 放在公网服务, 所以就查查资料, 尝试部署一套有SSL加密传输的, 而且有认证和权限控制机制的Kafka集群.
-
我之前对ZK的认证机制不了解, 也几乎不在JAVA生态圈有过经验, 所以对JAAS完全不了解. 对SASL也是首次接触. 因为kafka官方文档写的实在太简单(仅仅是指https://kafka.apache.org/documentation.html#zk_authz_new这一节), 在尝试和翻阅了好多(过时的)资料之后, 终于算是成功部署了. 但依然很多不知其所以然的地方.
-
对SSL有一定了解, 对Listenr配置也有一定了解了 . 所以打算先看一下Zookeeper的认证权限控制, 这个之前还没有接触过.
对ZooKeeper认证与权限控制目的
大的目的很简单, 因为提供对公的服务, 相比公司内部使用来说, 有安全隐患, 需要做一定的安全保护措施, 也就是上面提到的, “有SSL加密传输的, 而且有认证和权限控制机制的Kafka集群”.
具体怎么样做到”更安全”这个目的呢?(也就是我们的更精确一些的目的是什么呢?) 引述一下kafka官方文档中一段话.
The metadata stored in ZooKeeper for the Kafka cluster is world-readable, but can only be modified by the brokers. The rationale behind this decision is that the data stored in ZooKeeper is not sensitive, but inappropriate manipulation of that data can cause cluster disruption. We also recommend limiting the access to ZooKeeper via network segmentation (only brokers and some admin tools need access to ZooKeeper).字面意思很明确, ZK 中存的元信息是任何人都可读的, 但是只能被 Kafka Broker 修改, 因为这些信息不是敏感信息, 但随意改动却可能对 Kafka 造成破坏. 另外建议在网络层面隔离 ZK (因为只有 Broker 和一些管理工具才需要访问Zk )
我的理解是, 官方建议网络层面隔离ZK, 但是 ZK 本身也会有这样一种选择: 不能匿名登陆, 只可以让认证用户登陆. 但是实践下来, 并非如此. (此处存疑, 后面需要查阅ZK文档). 实践下来的”结论”比较奇怪: ZK 通过 JAAS 设置了用户(以及密码), Kafka 需要使用配置过的用户连接 ZK 并设置ACL. 但是, 1, 匿名用户依然可以连接 ZK, 也可以创建 Znode, 以及对 Znode 设置权限. 只是对 Broker 已经创建并设置好ACL的 Znode 只有只读权限. 2. Kafka 一定要是 JAAS 中配置用户(以及相对应的密码), 否则就会创建 Znode 失败. 1和2两点似乎是矛盾的.
配置步骤
配置 ZK 的认证
ZK 的认证配置可以参考(这个文档是说ZK节点之间的认证, 但Kafka到ZK的认证也就多了一步) https://cwiki.apache.org/confluence/display/ZOOKEEPER/Server-Server+mutual+authentication, 这里有详细的权威的步骤以及说明, 我简单记录一下吧.
我想提前先提一下 JAAS 配置, 因为这里有个还不明白的地方. ZK 以及 Kafka, 他们的 JASS 配置文件的格式都是一样的, 但简单看了一下 JAAS 的文档, 并没有看到针对这种格式的说明, 所以不明白这种格式是标准, 还是只是 ZK/Kafka 自己定义的格式. 另外, 对于里面的参数, 比如
username=XXX, 是有一个标准, 还是大家各自实现自己的, 也不清楚. [存疑]zoo.cfg 配置
将下面配置写入 zoo.cfg. 先提一下注意点, 里面的第2行第3行是 Zk 节点之间的认证开关, 并不影响 Kafka 到 ZK 的认证.
quorum.auth.enableSasl=true quorum.auth.learnerRequireSasl=true quorum.auth.serverRequireSasl=true quorum.auth.learner.loginContext=QuorumLearner quorum.auth.server.loginContext=QuorumServer #quorum.auth.kerberos.servicePrincipal=servicename/_HOST quorum.cnxn.threads.size=20因为我们没有使用 kerberos, 所以把第6行注释了.
解释一下各行的意思:
quorum.auth.enableSasl=true
打开sasl开关, 默认是关的
quorum.auth.learnerRequireSasl=true
ZK做为leaner的时候, 会发送认证信息
quorum.auth.serverRequireSasl=true
设置为 true 的时候, learner 连接的时候需要发送认证信息, 否则拒绝.
quorum.auth.learner.loginContext=QuorumLearner
JAAS 配置里面的 Context 名字.
quorum.auth.server.loginContext=QuorumServer
JAAS 配置里面的 Context 名字.
quorum.cnxn.threads.size=20
建议设置成 ZK 节点的数量乘2
bin/zkEnv.sh 添加 jvm 选项
SERVER_JVMFLAGS="-Djava.security.auth.login.config=/path/to/server/jaas/file.conf"具体的路径自己配置一下, 另外最好确认一下 SERVER_JVMFLAGS 是不是被使用了, 因为版本不断迭代, 后面也许会有变化.
JAAS 配置
Server { org.apache.zookeeper.server.auth.DigestLoginModule required user_super="123456" user_kafka="123456" user_someoneelse="123456"; }; QuorumServer { org.apache.zookeeper.server.auth.DigestLoginModule required user_zookeeper="123456"; }; QuorumLearner { org.apache.zookeeper.server.auth.DigestLoginModule required username="zookeeper" password="123456"; };QuorumServer 和 QuorumLearner 都是配置的 ZK 节点之间的认证配置, 我们叫他 Server-to-Server authentication , 并不影响 Kafka 的连接认证. Server 是配置的Kafka连接需要的认证信息, 我们叫他 Client-to-Server authentication
按我的理解说一下配置意思, 不一定准确.
QuorumServer 和 QuorumLearner 是指 Context 名字, 默认是这样的, 但可以通过上面提到的配置更改默认名字.
QuorumServer 里面的 user_zookeeper=”123456” , 是特定格式, 代表一个密码为123456的用户, 用户名是zookeeper, Learner 连接的时候需要使用这个用户/密码认证.
QuorumLearner 里面的配置是说, 做为 learner 连接的时候, 使用配置的用户名/密码认证.
下面是我还不明白的地方, 现在只能不负责任的说一下. [存疑]
org.apache.zookeeper.server.auth.DigestLoginModule 应该是指的认证方式, 有些文章中说, 和 Kafka 的 JAAS 配置需要一致, 但我测试下来并非如此.
我自己实践下来, ZK 中一定要使用 org.apache.zookeeper.server.auth.DigestLoginModule, 但Kafka中可以使用 org.apache.zookeeper.server.auth.DigestLoginModule, 也可以使用 org.apache.kafka.common.security.plain.PlainLoginModule对机制并不明白, 所以也是云里雾里.
对于 Server Context 配置, RedHat 文章中说, super 用户自动获得管理员权限. 我也不明白为啥, 在这里可以配置多个用户, Kafka 选一个用就可以了, 一般我们起名叫 kafka.
打开 Client-to-Server authentication
把下面的配置写到 zoo.cfg
requireClientAuthScheme=sasl authProvider.<IdOfBroker1>=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.<IdOfBroker2>=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.<IdOfBroker3>=org.apache.zookeeper.server.auth.SASLAuthenticationProvider这里的IdOfBroker是指ZK节点的myid. 后面的 org.apache.zookeeper.server.auth.SASLAuthenticationProvider 是指什么还不明白 [存疑]
ZK 的配置就到这里了, 权限控制(ACL)是另外一个话题. 后面再说.
紧接着说一下 , 如何配置 Kafka 使用认证连接 ZK.
Kafka 需要的配置
打开开关
在 config/server.properties 里面添加下面一行配置
zookeeper.set.acl=trueJVM选项中配置JAAS配置文件路径信息
在合适的地方, 添加下面这样的配置, 我在 bin/kafka-run-class.sh 添加的
KAFKA_OPTS="-Djava.security.auth.login.config=./config/jaas.conf"配置 JAAS
jaas.conf 配置中添加如下内容
Client { org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="123456"; };这样起来之后, Kafka 创建和使用的 Znode 都会被设置了ACL, 其他用户只能看, 不能修改.
-
-
算法导论笔记 6-3 建堆
先写一个 go 语言的程序如下
package main import ( "fmt" "math" "math/rand" "strings" "time" ) func maxHeapify(A []int, i int) { var ( size = len(A) left int right int max int ) for { left = 2*i + 1 right = 2*i + 2 max = i if left < size && A[i] < A[left] { max = left } if right < size && A[max] < A[right] { max = right } if max == i { return } A[i], A[max] = A[max], A[i] i = max } } func buildMaxHeap(A []int) { length := len(A) for i := length/2 - 1; i >= 0; i-- { maxHeapify(A, i) } } func GA(N int) (A []int) { A = make([]int, 10) for i := 0; i < N; i++ { A[i] = N - i } A[0] = 0 return } func RGA(N int) (A []int) { rand.Seed(time.Now().UnixNano()) A = make([]int, 10) for i := 0; i < N; i++ { A[i] = rand.Intn(N * N) } return } func isHeap(A []int) bool { size := len(A) for i := 0; i < size; i++ { left := 2*i + 1 right := 2*i + 1 if left < size && A[left] > A[i] { return false } if right < size && A[right] > A[i] { return false } } return true } func printTree(A []int) { var ( currentHeight = 0 startOfCurrentLine = 0 height = int(math.Ceil(math.Log2(float64(len(A)) + 0.5))) ) for i := 0; i < len(A); i++ { if i == startOfCurrentLine { jstring := make([]string, height-currentHeight) for j := 0; j < height-currentHeight; j++ { jstring[j] = " " } currentHeight++ fmt.Printf("\n%s", strings.Join(jstring, "")) startOfCurrentLine = 2*startOfCurrentLine + 1 } fmt.Printf("%d ", A[i]) } fmt.Println("\n") } func main() { count := 100 for i := 0; i < count; i++ { A := RGA(10) //printTree(A) buildMaxHeap(A) fmt.Println(isHeap(A)) //printTree(A) } }6.3-1
略
6.3-2
我们的算法是基于上一节的 Max-Heapify 基础之上的, 即: 对每一个结节做 Max-Heapify 的时候, 需要他的子树已经是最大堆了. 自上而下不满足这个前提条件.
6.3-3
这个是为了证明建堆的时间复杂度是O(n) , 先不证了, 略
-
算法导论笔记 6.2 章 - 维护堆的性质
6.2-1
略
6.2-2
略
6.2-3
会停止比较, 不进入递归, 直接返回
6.2-4
因为 left 和 right 都大于 heap-size , 所以不会进去递归, 直接返回了
6.2-5
func maxHeapify(A []int, i int) { var ( size = len(A) left int right int max int ) for { left = 2*i + 1 right = 2*i + 2 max = i if left < size && A[i] < A[left] { max = left } if right < size && A[max] < A[right] { max = right } if max == i { return } A[i], A[max] = A[max], A[i] i = max } }6.2-6
对于已经倒排排序的数组A, 把A[-1]提到最前面, 这个时候, max_heapify 的运行时间就是 ln(n), 像
[1,9,8,7,6,5,4,3,2] -
算法导论 第6章 堆
写在最前
-
节点A的高度 h 的定义是, A到叶子节点的边的个数. 所以 1,2,3 这个堆的高度是1
-
证明 i 的子节点是 2i+1 和 2i+2 , 可以用数据归纳法证明. 如果对于 i 成立, 那么 i+1 的子节点是 2i+2+1, 2i+2+2 , 所以对 i+1 也成立. 所以 i 的父节点是 floor(i/2)
6.1-1
先来计算高度为 h 的完全二叉树, 元素个数为多少.
第 i 层的元素个数是
2**(i-1), 设总元素个数S = 1 + 2 + 4 + ... + 2**(n-1)2 * S = 2 + 4 + ... + 2**nS= 2S-S= 2**n-1因为高度 h=n-1, 所以高度为 h 的堆中, 元素最多是
2**(h+1) - 1个, 最少是2**h个6.1-2
由 6.1-1 可知,
2**h <= n <= 2**(h+1) - 1=>h <= ln(n) < h+1=>h<=ln(n) && h > ln(n)-1, 所以h = ln(n).floor6.1-3
略吧
6.1-4
叶子结点上
6.1-5
是的, 因为满足定义 A[parent(i)] >= A[i]
6.1-6
不是 6 < 5
6.1-7
i 的父节点是 floor(i/2), 所以从 floor(i/2)+1 的节点都是没有子节点的, 也就是叶子节点
-
-
算法导论学习笔记5 随机算法
5.3-1
我觉得Marceau教授说的挺有道理. 我的想法是把i=2的时候做为初始状态, 只要证明交换过A[1]之后, 每种可能的子数组A[1..1]的概率是1/n. 这个结论应该是”明显”的.
5.3-2
按我的理解应该是不可以的. 如果初始的时候, 第一个数字是X的概率小, 那么程序跑完之后, 第一个数字不是X的概率就会变大, 而不 1/n 了.
我们来写程序来验证一下 5.3-1 和 5.3-2 的结果吧.
package main import ( "fmt" "math/rand" "time" ) func shuffle(array []int) { rand.Seed(time.Now().UnixNano()) var ( tmp int index int n = len(array) ) for i := 0; i < n; i++ { index = rand.Intn(n-i) + i tmp = array[index] array[index] = array[i] array[i] = tmp } } func generate_array(n int) []int { array := make([]int, n) for i := 0; i < n; i++ { array[i] = i } return array } func main() { var ( loop = 6000 N = 3 ) for i := 0; i < loop; i++ { array := generate_array(N) shuffle(array) fmt.Printf("%v\n", array) } }看5.3-1的结果, 还是很平均的.
% go run 5.3.1.go | sort | uniq -c 990 [0 1 2] 1038 [0 2 1] 965 [1 0 2] 991 [1 2 0] 1002 [2 0 1] 1014 [2 1 0]5.3-2的结果, 第一位永远不是0
package main import ( "fmt" "math/rand" "time" ) func shuffle(array []int) { rand.Seed(time.Now().UnixNano()) var ( tmp int index int n = len(array) ) for i := 0; i < n-1; i++ { index = rand.Intn(n-i-1) + i + 1 tmp = array[index] array[index] = array[i] array[i] = tmp } } func generate_array(n int) []int { array := make([]int, n) for i := 0; i < n; i++ { array[i] = i } return array } func main() { var ( loop = 6000 N = 3 ) for i := 0; i < loop; i++ { array := generate_array(N) shuffle(array) fmt.Printf("%v\n", array) } }% go run 5.3.2.go | sort | uniq -c 2951 [1 2 0] 3049 [2 0 1]5.3-3
这些题目.. 都是谁想来杀我脑细胞的..
完全用教材中的示例去套已经不行了, 得到的结果貌似是”不能证明”. 但是直觉感觉是可以的. 先放下, 来写个程序验证下吧.
package main import ( "fmt" "math/rand" "time" ) func shuffle(array []int) { rand.Seed(time.Now().UnixNano()) var ( tmp int index int n = len(array) ) for i := 0; i < n-1; i++ { index = rand.Intn(n) tmp = array[index] array[index] = array[i] array[i] = tmp } } func generate_array(n int) []int { array := make([]int, n) for i := 0; i < n; i++ { array[i] = i } return array } func main() { var ( loop = 6000 N = 3 ) for i := 0; i < loop; i++ { array := generate_array(N) shuffle(array) fmt.Printf("%v\n", array) } }运行结果
% go run 5.3.3.go | sort | uniq -c | sort -k2 892 [0 1 2] 1157 [0 2 1] 1073 [1 0 2] 1123 [1 2 0] 864 [2 0 1] 891 [2 1 0]第一位是2的概率小一些.. 想了一会, 用一个反例来证明这个办法不行吧.
比如 0 1 2 这三个排列好的数字, 用5.3.3的程序来跑, 我们来算一下跑完之后2出现在第一位的概率, 是 4/27 . 这样应该能证明这个算法是错误的了. 我最开始的直觉是错的.
又想了一会, 想到一个更好些的证明吧.
不失普遍性, 我们假设n=10好了. 在进行到最后一步的时候, 设特定的数字x(比如说1)出现在第1位的概率是p, 那么最后一步进行之后, x在第一位的概率是 p*9/10 , p*9/10=1/10 => p=1/9. 同理, x出现在第2-9位的概率也是1/9, 加起来的概率为1, 也就是说x出现在最后的概率需要为0, 显然前面进行的操作到最后一步时, 满足不了x在最后出现的概率为0, 那也保证不了最后一步之后, 这个数列是个随机数列.
5.3-4
我看教材的时候, 里面说, 如果数列中的每一个特定的数字出现在一个特定位子的概率都是1/n, 也不能保证他就是一个随机数组, 我就想这会是什么情况呢? 这个题目给出了一个简单又有力的反例.
如果初始数组不是随机的, 比如是0,1,2,3,4,5,6,7,8,9, 那么这个算法过后, 每个元素A[i]出现在任意特定位置的概率都是1/n (因为offset是1-n中每个数字的概率就是1/n), 但他显然不是随机数组, 因为初始数列的排列并没有打乱.
5.3-5
优先级数列中, 每个数字都不一样的概率如下, 记
N=n**3, 则概率为p=(N-1)*(N-2)*(N-3)*...*(N-n)/N**n,p > (N-n)**n/N**n = ((N-n)/N)**n = (1-n/N)**n, 只需要证明(1-1/n**2)**n > 1-1/n, 这个不知道怎么证明, 只是写程序看出来, 这里的2不能再小了, 哪怕小于1.99, 这个不等式也是不成立的. #TODO#5.3-6
最简单的实现应该是保证没有重复的优先级. 如果想快一些就第一次先不管, 然后再对重复的部分排序一次, 这次保证没有重复的优先级.
package main import ( "fmt" "math/rand" "sort" "time" ) func permute_by_sorting(array []int) []int { rand.Seed(time.Now().UnixNano()) var ( n = len(array) N = n * n * n priority_array = make([]int, n) sorted_priority_array = make([]int, n) // sort priority_array to sorted_priority_array shuffled_array = make([]int, n) existed = map[int]bool{} ) for i := 0; i < n; i++ { r := rand.Intn(N) for { if _, ok := existed[r]; !ok { break } r = rand.Intn(N) } existed[r] = true priority_array[i] = r sorted_priority_array[i] = priority_array[i] } sort.Slice(sorted_priority_array, func(i, j int) bool { return sorted_priority_array[i] < sorted_priority_array[j] }) idx_map := make(map[int]int) for i := 0; i < n; i++ { if _, ok := idx_map[sorted_priority_array[i]]; !ok { idx_map[sorted_priority_array[i]] = i } } for i := 0; i < n; i++ { shuffled_array[i] = -1 } for i := 0; i < n; i++ { e := priority_array[i] new_idx := idx_map[e] for shuffled_array[new_idx] != -1 { new_idx++ } shuffled_array[new_idx] = array[i] } return shuffled_array } func main() { var ( N = 2 loop = 6000 ) array := make([]int, N) for i := 0; i < N; i++ { array[i] = i } for i := 0; i < loop; i++ { shuffled_array := permute_by_sorting(array) fmt.Println(shuffled_array) } }5.3-6
归纳法. 假设
random_sample(n-1, m-1)返回的子集中, 每一个数字出现的概率都是(m-1)/(n-1). 接下来的一步中, 选到 n 的概率是1/n + (m-1)/n = m/n, 选到不是 n 的其他特定一个数字的概率是(m-1)/(n-1) + ((n-m)/(n-1)) * (1/n) = m/n初始情况分析, 我还是觉得 Marceau 教授说的有道理, 从 m == 1 分析更符合人的常识吧.
package main import ( "fmt" "math/rand" "sort" "time" ) func random_sample(n []int, m int) []int { if m == 0 { return []int{} } length := len(n) //fmt.Println(length) s := random_sample(n[:length-1], m-1) i := n[rand.Intn(length)] var in_s = false for _, j := range s { if j == i { in_s = true break } } if in_s { s = append(s, n[length-1]) } else { s = append(s, i) } return s } func main() { rand.Seed(time.Now().UnixNano()) var ( loop = 10000 N = 5 m = 3 ) array := make([]int, N) for i := 0; i < N; i++ { array[i] = i } for i := 0; i < loop; i++ { s := random_sample(array, m) sort.Slice(s, func(i, j int) bool { return s[i] <= s[j] }) fmt.Println(s) } } -
算法导论 笔记4 5.2-指示器随机变量
看完之后, 还一时不能熟练理解和应用
5.2-1
正好雇一次的概率是, 最优秀的人出现在第一个的概率, 就是 1/n
雇佣n次的概率是, 所有人正好按从弱到强来面试的概率, 是 1/n!
5.2-2
比如有n个面试者, 第一个出现的肯定要被录取, 设第一个的能力排名是i . 那后面的n-1个人里面, 第 i+1 名之后的这些人, 怎么出现都无所谓, 因为他们肯定不会被录取了. 就看排名在 i 之前的这些人, 一共有 i-1 个人, 他们需要满足且仅需要满足: 排名第1的那个人最先出现, 概率是 1/(i-1)
所以如果第一个人是第2名(概率是1/n), 那么后面录取一个人概率是 1/1,
如果第一个人是第3名(概率是1/n), 那么后面录取一个人概率是 1/2
如果第一个人是第4名(概率是1/n), 那么后面录取一个人概率是 1/3
…
如果第一个人是第n名(概率是1/n), 那么后面录取一个人概率是 1/(n-1)所以总的概率是 (1+1/2+1/3+…+1/(n-1))/n
我们来模拟一下吧, 看看这个结果对不对.
写一个go的程序, 来输出一下理论上的概率值, 以及模拟出来的”真实”概率. (概率乘了人数 n 然后输出的, 为了和后面提到的欧拉公式做验证)
package main import ( "flag" "fmt" "math/rand" "time" ) func P(n int) float32 { var s float32 = 0.0 for i := 2; i <= n; i++ { s += 1 / float32(i-1) } return s / float32(n) } func interview(candidates []int) int { var ( best = 0 hire_loop_count = 0 ) for _, c := range candidates { if c > best { best = c hire_loop_count++ } } return hire_loop_count } func generate_candidates(n int) []int { var ( candidates = make([]int, 0) exist = make(map[int]bool) candidate int ) for len(candidates) < n { candidate = rand.Intn(5*n) + 1 if _, ok := exist[candidate]; ok { continue } else { exist[candidate] = true candidates = append(candidates, candidate) } } return candidates } var ( loop_count int N int ) func init() { rand.Seed(time.Now().Unix()) flag.IntVar(&loop_count, "loop-count", 100, "") flag.IntVar(&N, "N", 100, "") flag.Parse() } func main() { // theory for n := 2; n < N; n++ { p := P(n) fmt.Printf("%d %f %f\n", n, p, p*float32(n)) } return // real var candidates []int for n := 2; n <= N; n++ { c := 0 for i := 0; i < loop_count; i++ { candidates = generate_candidates(n) if interview(candidates) == 2 { c++ } } fmt.Printf("%d %d %f\n", n, c, float32(c)/float32(loop_count)*float32(n)) } }然后用python+plt把图画出来看一下.
import matplotlib.pyplot as plt import math X_REAL = [] Y_REAL = [] for l in open('real.txt').readlines(): l = l.strip() if l: x, _, y = l.split() x, y = int(x), float(y) X_REAL.append(x) Y_REAL.append(y) X_THEORY = [] Y_THEORY = [] for l in open('theory.txt').readlines(): l = l.strip() if l: x, _, y = l.split() x, y = int(x), float(y) X_THEORY.append(x) Y_THEORY.append(y) X_Euler = range(2, len(X_THEORY)+2) Y_Euler = [math.log(x-1) + 0.577 + 1/2/(x-1) for x in X_Euler] plt.plot(X_REAL, Y_REAL, 'g', X_THEORY , Y_THEORY, 'rs', X_Euler, Y_Euler, 'b^') plt.show()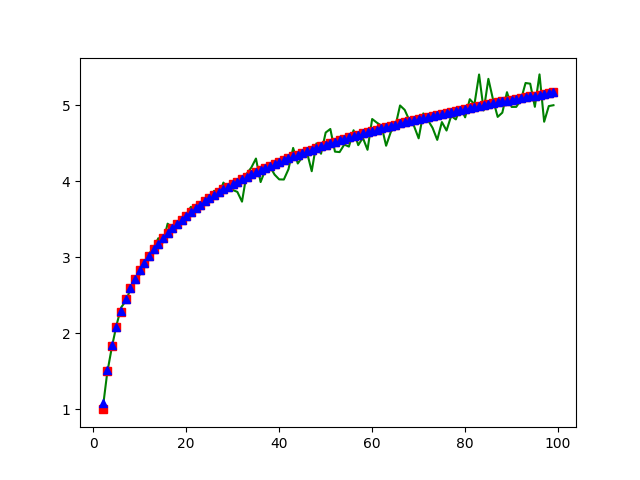
绿色是真实的数据, 红色是理论数据(1+1/2+…+1/(n-1))算出来的, 蓝色是欧拉公式算出来的. 还是符合的不错的. 欧拉公式参考https://zh.wikipedia.org/wiki/调和级数
题外.
因为最近在看机器学习, 感觉这个是一个可以用来学习的例子, 拿tensorflow来学习一下”真实概率”的数据, 看看学习效果怎么样.
from __future__ import print_function import tensorflow as tf import numpy as np X = [] Y = [] for l in open('real.txt').readlines(): l = l.strip() if l: x, _, y = l.split() x, y = float(x), float(y) X.append(x) Y.append(y) X = tf.cast(np.array(X), tf.float32) Y = tf.cast(np.array(Y), tf.float32) # Weights_1 = tf.Variable(tf.random_uniform([1], -1.0, 1.0), dtype=tf.float32) # Weights_2 = tf.Variable(tf.random_uniform([1], -1.0, 1.0), dtype=tf.float32) Weights_3 = tf.Variable(tf.random_uniform([1], -1.0, 1.0), dtype=tf.float32) biases = tf.Variable(tf.zeros([1])) # y = Weights_1*X*X + Weights_2*X + biases + Weights_3 * tf.math.log(X) y = biases + Weights_3 * tf.math.log(X) loss = tf.reduce_mean(tf.square(y-Y)) # optimizer = tf.train.GradientDescentOptimizer(0.000001) optimizer = tf.train.AdamOptimizer(0.75) train = optimizer.minimize(loss) with tf.Session() as sess: init = tf.global_variables_initializer() sess.run(init) for step in range(100000): sess.run(train) if step % 100 == 0: print(step, sess.run(Weights_3), sess.run(biases), sess.run(loss))个人感觉效果还算可以吧.
5.2-3
n*(1+2+3+4+5+6)/6
我觉得这个使用指示器变量的想法是很自然的, 反而一般人不会使用”正统”的方法去计算, 所以正统方法就是, n个0的概率0 + n-1个0和1个1的概率1 + … + n个6的概率*6n
5.2-4
每个人拿到自己帽子的概率是 1/n , 所以期望是 1
5.2-5
看第i个数字, 前面有i-1个数字, 每一个比i大的概率是1/2, 所以i前面比i大的数字的个数期望是 (i-1)/2 , 那对i从1取到n, 得到题目答案应该是 西格玛(i-1)/2 i从1到n
验证下看吧.
package main import ( "fmt" "math/rand" "time" ) func generate_nums(n int) []int { rand.Seed(time.Now().UnixNano()) var ( nums = make([]int, 0) exist = make(map[int]bool) num int ) for len(nums) < n { num = rand.Intn(n) if _, ok := exist[num]; ok { continue } else { exist[num] = true nums = append(nums, num) } } return nums } func inversion_count(nums []int) int { var count = 0 for i, n1 := range nums { for _, n2 := range nums[:i] { if n1 < n2 { count++ } } } return count } func theory(n int) float32 { var s float32 = 0.0 for i := 1; i <= n; i++ { s += float32(i-1) / 2 } return s } func main() { var ( N = 100 count = 1000 ) total := 0 for i := 0; i < count; i++ { nums := generate_nums(N) inversion_count := inversion_count(nums) total += inversion_count } fmt.Printf("%f %f\n", theory(N), float32(total)/float32(count)) }% go run 5.2.5.go 2475.000000 2463.620117 -
算法导论 笔记3 5.1-雇佣问题
5.1-1
我是看的中文版本, 我觉得这个翻译的不对, 应该是说满足
全序关系. 首先要理解什么是全序关系的集合, 这是一个严格的数学定义. 参考https://zh.wikipedia.org/wiki/全序关系全序关系即集合 X 上的反对称的、传递的和完全的二元关系还有一点就是, ‘在第四行的代码中, 总能决定哪一个应聘者最佳’, 不是说’运行一次这个代码, 第四行的代码都可以决定哪个最佳’ , 而是说不管如何随机, 不管如何打乱应聘者顺序, 运行多次, 乃至无数次, 第四行的代码都可以决定哪个最佳. 如果不这么理解, 全序关系就正明不了.
我不知道怎么算是严格的数学意义上的证明, 简单说一下吧.
反对称性, 若 a>=b && b>=a, 则 a==b . 关于反对称性, 我觉得, 还有另外一个翻译不准确的地方, ‘总能决定哪一个应聘者最佳’, 是说两两比较总能区分哪一个更好, 不能出现一样好的情况. 如果单看代码的话, 是有可能出现 a == b 的. 如果所有应聘者都是能力相同, 那么反对称性就满足不了了. 按自我纠正后的理解呢, 可以用反证法证明: 如果不满足反对称, 则A和B就不是’总能区分哪一个更好’, 所以一定满足反对称性.
传递性, 这个真不知道怎么算’证明’, A比B好, B比C好, A’明显’比C好, 这个需要证明吗?
完全性, a<=b, 或者 b<=a . 既然’总能区分哪一个更好’, 说明a和b总有一个比另外一个好. 用反证更好理解: 如果不满足完全性, 就是说a和b不能比较哪个更好, 这样就不能保证’总能区分哪一个更好’, 所以一定要满足完全性.
5.1-2
这个问题我想了好几天, 终于没想出来一个可靠的好办法, 网上搜索了别人的回答, 和我的一样不算可靠, 看来只能这样了.
先说下我的思路.
- 假设已有 rand(1, n), 返回 1-n 之间随机一个数字. 这里的n是所有2的整数次方, 2, 4, 8, 16 … 1024 …
- 求 rand(1, x), 只需要按下面这样, 先找一个比x大的n r = rand(1, n) while r > x: r = rand(1, n) return r
- 现在的问题就是假设1 能不能实现, 怎么实现. 这个很简单.
rand(1, 2*n) = rand(1, n) * rand(1, 2)
网上看到的回答, 基本原理是一样的, 但合在一步里面了, 并不需要先求 rand(1, n)
对于 rand(1, x), 先找一个最小的n,使 pow(2,n) >= x, 比如求 rand(1,5), 则取 n=3 , 然后
r = x + 1 while r > n { r = 0 for i = 1; i <= n; i++ { r = 2*r + rand(0,1) } } return n我说他不可靠, 是因为这个
while r > x的条件可能永远达成不了, 最坏时间复杂度应该是无限大吧, 但还是可以计算一下平均时间复杂度. 我算下来, 平均时间复杂度是 O(n), 这里的n不是x, 就是上面描述里面的n. 精确的说, 平均运行时间是2n计算方式如下:
首先呢, 如果x正好是2的某整数次方, 那么不会死循环, 一次过! 坏情况是x正好是2的某整数次方+1, 这种情况下, 一次过的概率只有1/2, 还有1/2的概率需要重新再来一次.
设期望运行时间, 也就是
r = 2*r + rand(0,1)这行代码的运行次数的期望, 为 f(n), 那么 f(n) = 1/2 * n + 1/2 * (1+f(n)) , 求得 f(n) = 2n写了个程序验证了一下运行时间
# -*- coding: utf-8 -*- import random import time import sys import math count = 0 def f(x, n): global count r = x + 1 while r >= x: r = 0 for _ in range(n): count += 1 r = 2*r + random.randint(0, 1) return r if __name__ == '__main__': x = int(eval(sys.argv[1])) n = int(math.ceil(math.log(x, 2))) print x,n for _ in range(10000): f(x, n) print count/10000.0运行结果
% python a.py "2**9+1" 513 10 20.14 % python a.py "2**19+1" 524289 20 40.0385.1-3
# -*- coding: utf-8 -*- import sys import random count = 0 def fp(p=float(sys.argv[1])): if random.random() <= p: return 0 return 1 def f2(): global count while True: count += 1 x = fp() - fp() if x == 1: return 0 if x == -1: return 1 if __name__ == '__main__': for _ in range(100000): f2() print count / 100000.0运行结果:
% python a.py 0.3 2.36684 % python a.py 0.5 2.00161 % python a.py 0.1 5.56982 % python a.py 0.9 5.56247运行时间期望分析. 函数f2中不能返回的概率是
p**2 + (1-p)**2, 记为x, 能返回的概率则是 1-x设运行时间的期望是 E , 也就是代码中count的期望值(平均值).
E = 1-x + x(1+E), 得到 E = 1/(1-x)
另外一种计算方式
前面提到的这种计算方式, 总觉得有些怪怪(应该是还没有形成这种思维), 有种无限递归的感觉. 所以再用另外一种方法来算一次, 拿第三个题目做例子.
p和x的意义见上面, 记期望为E
-
一次就得到结果的概率是
1-x, 两次得到结果的概率是(1-x)*x, 三次得到结果的概率是(1-x)*x**2, … , n次得到结果的概率是(1-x)*x**n -
所以期望
E = (1-x) + 2(1-x)x + 3(1-x)*x**2 + ... + n(1-x)*x**(n-1) -
把 (1-x) 去掉, 记
S = 1 + 2x + 3x**2 + ... + n*x**(n-1), -
两边乘x, 得
xS = x + 2x**2 + 3x**3 + n*x**n, -
两个等式想减, 得到
S-xS = 1 + x + x**2 + x**3 + ... + x**(n-1) - n*x**n -
记
f = 1 + x + x**2 + x**3 + ... + x**(n-1), 两边各乘 x, 得xf = x + x**2 + x**3 + ... + x**n, 两个等式两边相减, 得到f-xf = 1-x**n, 所以f=(1-x**n)/(1-x). 因为 x < 1, 而且 n 趋向于无穷大, 所以x**n = 0, 所以f=1/(1-x) -
根据5和6, 得到
S-xS = 1/(1-x) - n*x**n = 1/(1-x)所以 `S = 1/(1-x)**2’ -
将7代入2, 得到期望
E = 1/(1-x)
-
算法导论 笔记2 4.2-矩阵乘法Strassen算法
4.2.1 使用Strassen计算
[1 3][6 8] [7 5][4 2]先手工算一下答案记下来
[18 14] [62 66]完全参考书的步骤来做一下这个题目
- 分解矩阵 略
-
创建并计算10个矩阵
S1 = B12 - B22 = [6] S2 = A11 + A12 = [4] S3 = A21 + A22 = [12] S4 = B21 - B11 = [-2] S5 = A11 + A22 = [6] S6 = B11 + B22 = [8] S7 = A12 - A22 = [-2] S8 = B21 + B22 = [6] S9 = A11 - A21 = [-6] S10 = B11 + B12 = [14] -
计算7次矩阵乘法
P1 = A11 * S1 = [6] P2 = S2 * B22 = [8] P3 = S3 * B11 = [72] P4 = A22 * S4 = [-10] P5 = S5 * S6 = [48] P6 = S7 * S8 = [-12] P7 = S9 * S10 = [-84] -
计算 C11 C12 C21 C22
C11 = P5 + P4 - P2 + P6 = [18] C12 = P1 + P2 = [14] C21 = P3 + P4 = [62] C22 = P5 + P1 - P3 - P7 = [66]
没有纸笔, 靠我的脑子想不出来, 我先跳到第五章吧.
-
算法导论 读书笔记1
先占个坑, 督促自己一下.
2018-11-04T19:55:28+0800
4.1.1
返回数组里面的最大值, 例子参见下面的 4.1.2
4.1.2
def find_maximum_subarray(A): maximum_subarry_sum = None rst = (None, None) for i in range(len(A)): sum_of_array_i_to_j = 0 for j in range(i, len(A)): sum_of_array_i_to_j += A[j] if sum_of_array_i_to_j > maximum_subarry_sum: maximum_subarry_sum = sum_of_array_i_to_j rst = (i, j) return rst if __name__ == '__main__': A = [13, -3, -25, 20, -3, -16, -23, 18, 20, -7, 12, -5, -22, 15, -4, 7] i, j = find_maximum_subarray(A) print(A[i: j+1]) import random A = [] for i in range(30): A.append(random.randint(-100, -1)) print(A) i, j = find_maximum_subarray(A) print(A[i: j+1])4.1.3
代码如下, 在我电脑测试时, 临界点为45. 当数组长度小于45时, 采用暴力算法, 显然不会改变性能交叉点. 但比如说, 当数组长度小于10时采用暴力算法, 可以改变性能交叉点.
# -*- coding: utf-8 -*- def find_maximum_subarray_1(A, low, high): """ 暴力运算 """ maximum_subarry_sum = None rst = (None, None) for i in range(low, high+1): sum_of_array_i_to_j = 0 for j in range(i, high+1): sum_of_array_i_to_j += A[j] if sum_of_array_i_to_j > maximum_subarry_sum: maximum_subarry_sum = sum_of_array_i_to_j rst = (i, j) return rst[0], rst[1], maximum_subarry_sum def find_maximum_subarray(A, low, high): """ 分治 """ if high - low <= 10: return find_maximum_subarray_1(A, low, high) mid = (low+high)/2 left_low, left_high, left_sum = find_maximum_subarray(A, low, mid) right_low, right_high, right_sum = find_maximum_subarray(A, mid+1, high) left_sum_part, array_sum = None, 0 for i in range(mid, low-1, -1): array_sum += A[i] if array_sum > left_sum_part: left_sum_part = array_sum max_left = i right_sum_part, array_sum = None, 0 for i in range(mid+1, high+1): array_sum += A[i] if array_sum > right_sum_part: right_sum_part = array_sum max_right = i if left_sum_part+right_sum_part > max(left_sum, right_sum): return max_left, max_right, left_sum_part+right_sum_part if left_sum > right_sum: return left_low, left_high, left_sum return right_low, right_high, right_sum def main(): import time import random import sys A_length = int(sys.argv[1]) A_count = int(sys.argv[2]) if sys.argv[2:] else 1000 all_A = [] for i in range(A_count): all_A.append([random.randint(-100, 100) for _ in range(A_length)]) start_time = time.time() for i in range(A_count): find_maximum_subarray_1(all_A[i], 0, A_length-1) end_time = time.time() print(u'暴力 %.2f' % (end_time - start_time)) start_time = time.time() for i in range(A_count): find_maximum_subarray(all_A[i], 0, A_length-1) end_time = time.time() print(u'分治 %.2f' % (end_time - start_time)) if __name__ == '__main__': main()4.1.4
如果最终的结果maximum_subarry_sum是小于0的, 那么就返回一个空数组
4.1.5
个人感觉, 完全按题干中的”如下思想”来写, 时间复杂度并不是O(n), 而是O(n*2). 因为第一层需要遍历1..n, 当遍历到j的时候, 第二层最坏情况下, 需要遍历i..j.
动态规划的话,还需要一个额外的数组, 叫它 maximum_subarry_endswith_j, 记录的是A[:j]里面以A[j]结尾的最大子数组. 能避免第二层的O(n)的复杂度. 代码如下:
def find_maximum_subarray_2(A, low, high): """ 动态规划 """ maximum_subarry = (-1, -1, None) maximum_subarry_endswith_j = [] maximum_subarry = (low, low, A[low]) maximum_subarry_endswith_j.append((low, A[low])) for j in range(low+1, high+1): _start, _max_sum = maximum_subarry_endswith_j[-1] if _max_sum < 0: maximum_subarry_endswith_j.append((j, A[j])) else: maximum_subarry_endswith_j.append((_start, _max_sum + A[j])) if maximum_subarry_endswith_j[-1][1] > maximum_subarry[-1]: maximum_subarry = (maximum_subarry_endswith_j[-1][0], j, maximum_subarry_endswith_j[-1][1]) return maximum_subarry数组长度100, 跑1000个100长度的随机的数组, 时间如下:
% python c.py 100 1000 暴力 0.71 分治 0.23 动态规划 0.06 % python c.py 200 1000 暴力 2.57 分治 0.48 动态规划 0.11 % python c.py 400 1000 暴力 10.25 分治 1.08 动态规划 0.23 -
nginx配置中的if条件与querystring配置例子
set $search 0; if ($request_uri ~ "_search"){ set $search 1; } if ($request_uri ~ "_count"){ set $search 1; } if ($arg_ignore_unavailable = true) { set $search "${search}1"; } if ($search = 1) { set $args $args&ignore_unavailable=true; } if ($arg_preference = "") { set $args $args&preference=$upstream_http_django_user; }