-
hangout中GeoIP2的性能统计
在hangout里面, 有个GeoIP2插件, 可以根据IP添加地理信息. 我们在使用这个插件之后, 发现处理速度有些下降, 于是通过日志统计了一下这个插件的性能.
我们是跑在marathon + docker平台上的, 可能统计会有所偏差.
每批60000条数据, 处理好之后, bulk到ES. 日志会记录bulk的时间, 和bulk结束拿到response的时间, 根据这两个时间统计.
使用GeoIP2之前的 filter: 234055次 平均8.51832039051秒 (不包括GeoIP2, 但有其他的Filter) bulk: 234048次 平均 5.99807413009秒 之后的 filter: 9145次 平均 13.0438958994秒 (在之前Filter的基础上, 添加了GeoIP2) bulk: 9146次 平均 3.70712070851秒后面bulk快可能是因为ES做过扩容.
但是filter时间多了4.5秒, 每批6W条数据, 平均一条数据0.000075秒. -
elasticsearch中rebalance策略分析及参数调整
在做一些维护的时候, 比如删除/关闭索引, ES会触发rabalance, 但有时候觉得它过于敏感了.
分析一些ES的rebalance策略是怎么样的, 有些不确定, 属于猜测.
举例现在web-2016.10.03正在weak节点上做rebalance:
web-2016.10.03 4 p RELOCATING 450308191 757.5gb 10.0.0.1 10.0.0.1-> 10.0.0.2 0zDpSrgmT1mSrtEywH86zg 10.0.0.2源10.0.0.1上面有52个shard, 目的10.0.0.2有48个shard. 总的shard 是33400, web-2016.10.03一共10shards, 无复制片, 共129个Node.
先按公式计算每个Node的weight (这个公式我不是很确定, 之前见到过, 但找不到了, 一部分凭印象, 部分参考代码https://github.com/elastic/elasticsearch/blob/2.4/core/src/main/java/org/elasticsearch/cluster/routing/allocation/allocator/BalancedShardsAllocator.java, 还有一部分算是蒙的吧)
1的权重是 0.45(52-33400/129)+0.55(1-10/129)
2的权重是 0.45(48-33400/129)+0.55(0-10/129)两个权重的差值是 0.45(52-48) - 0.55(1-0) = 2.34, 大于1.
第二个部分先认为是固定不变的(源不大可能大于1,毕竟总shard是10个, 加上复制片才20, 总节点远超过这个. 目标也一般是0) 所以主要影响因素就是0.45*(52-48), 如果想控制, 相差<=3的时候不做迁移, 阈值设置成2就可以.
-
elasticsearch中的common terms query
翻译自https://www.elastic.co/guide/en/elasticsearch/reference/2.3/query-dsl-common-terms-query.html
common terms query 是stopword一个替代方案(但我感觉比单纯的stopword好多了). 它可以提升精确度, 还不会牺牲性能.
The Problem
在Query中, 每个Term都消耗一定的资源. 搜索”The brown fox”需要三次term query, 这三个term都会在索引中的所有文档中执行,但是 “The” 这个term对相关性的影响比其他两个term要小.
之前的解决方法是把”the”这种高频词当成stopword, 可以减少索引大小, 在搜索的时候也会减少query次数.
但是, 虽然高频词对相关性的影响小, 但是他们依然很重要. 如果把stopword去掉, 会丧失精确性, 比如说”happy”, “not happy”就区分不了了. 而且, “The The” , “To be or not to be” 这种文本就丢失了.
解决方案
common terms query把query temrs分成2组, 一组是更重要的(低频词), 一组是不太重要的(高频词,之前被当成stopword).
第一步, 先搜索更重要的term, 它们是低频词, 对相关性的影响更大.
第二步, 再对高频词执行第二次搜索. 但是它不对所有匹配的文档打分, 只对第一步中匹配的文档打分. 这样的话, 高频词也可以提升结果的相关性, 同时还不会增加很多负载.
上面这个第二步没有很理解, 为什么不会增加很多负载. 因为对query的执行原理不清楚 :(
如果query里面的term全是高频词,那么query会按照 AND queyr来执行(默认是or). 这样的话, 虽然每个term都匹配好多文档, 但AND之后,结果集就会小很多.
也可以用 minimum_should_match 这个参数控制用 OR query, 最好使用一个大点的值~ -
TCP连接中的状态变迁
关于TCP的状态变迁, 这张截自TCP/IP协议详解一书的这张图,简单明了.
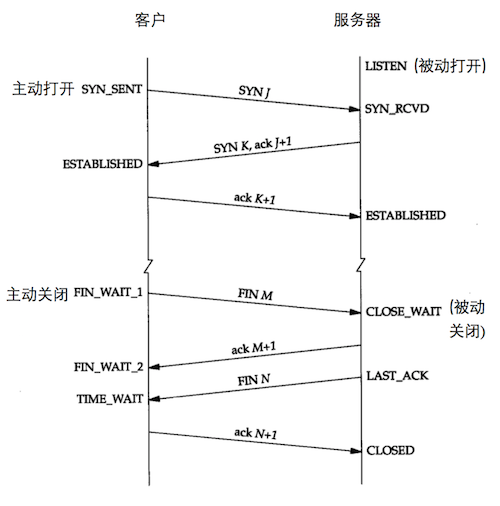
这篇文章总结一下各状态变迁对应的编程语言中对应哪一个方法调用.
-
幽灵堵车
如果你在高速公路上开过车,你可能会碰到这种情况。车流越来越慢……变的慢慢挪……然后最后完全停下来。几分钟之后,车流又依次开始移动,然后突然你就有可以全速行驶了。最匪夷所思的地方是,发生这种交通现象时,并没有任何施工、交通事故或其他可情况发生。到底这是为什么呢?
如果在高速公路上有足够多的车辆,任何轻微的交通流量中断,都会导致循环、放大式的连锁反应:一辆车轻轻地稍微刹了一下车,跟在后面的一辆车就会刹车得更重一点以免撞上前面那辆车,最后刹车量被逐级增大,直到产生交通流的波动、车流变慢甚至停止。
在网页上模拟 直观的感受下.
- 在200*200的正方行街区, 排列了一辆辆的汽车, 每辆车长3米, 相邻的两车间隔10米,以每秒20米的速度前行.
- 与前车间隔小于10米时,以0.2的系数减速.例如间隔8米时,速度降至20-2*0.2=19.6米/秒.
- 当与前车间隔小于4米时, 停止. 与前车距离大于50米时, 以30米/秒稳速行进.
- 第一秒时, 第一辆车因为某种原因停了5秒, 然后又正常启动.
- 红色是最慢的一辆车, 橙色是速度小于10米/秒的车
这5秒的故障会导致50秒的时候,还有车的速度低于10米/秒. 这时候第一辆车应该已经在1.4公里之外了. 但这个圈只有800米,所以他追上最后一辆时, 他的速度也只能在6米/秒, 它大概想不到这么慢的速度就是因为他自己停了5秒钟造成的.
-
利用nginx ngx_http_auth_request_module模块做ldap认证
nginx的一篇官方博客已经给出了非常详细的ldap认证办法, 并给出了示例代码
但我并不需要这么多步的跳转; 我需要的是一个就像Basic Auth一样简单的弹出登陆窗口, 因为第一我觉得用户(至少我)觉得弹出窗口简单够用, 第二, 最重要的, 这个可能是给api调用的, 如果api client那边做过多的跳转并不友好.代码放在https://github.com/childe/ldap-nginx-golang
需要提前了解的2个知识点
nginx auth_request
ldap认证功能的实现依赖nginx的auth_request这个模块, 但这个模块默认是不安装的, 需要编译nginx的时候加上–with-http_auth_request_module这个参数.
官方文档在http://nginx.org/en/docs/http/ngx_http_auth_request_module.html
简单解释一下:
location / { auth_request /auth-proxy; proxy_pass http://backend/; }这个意思是说, 所有访问先转到/auth-proxy这里, /auth-proxy如果返回401或者403, 则访问被拒绝; 如果返回2xx, 访问允许,继续被nginx转到http://backend/; 返回其他值, 会被认为是个错误.
WWW-Authenticate
这是一个http的header, 可以用来实现HTTP Basic authentication(BA). BA是对网站做权限控制的最简单的一个形式, 如图
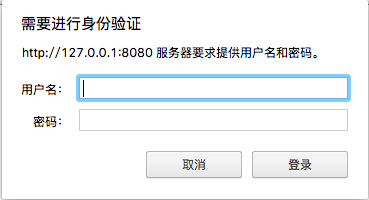
下面的内容参考https://en.wikipedia.org/wiki/Basic_access_authentication
它的实现原理是这样的
-
服务器端: 服务器返回401返回码, 并在header里面有如下格式的内容,代表此网页需要做Basic authenticate
WWW-Authenticate: Basic realm=””
- 客户端: 发送验证消息, 就是添加一个Authorization的header.
- username:password
- 对以上内容用base64编码
- 对编码后的内容前面加上”Basic “
最后的内容像下面这样:
Authorization: Basic QWxhZGRpbjpPcGVuU2VzYW1l
-
URL中编码: 客户端也可以在URL中把认证内容发送过去, 如下:
https://Aladdin:[email protected]/index.html
安全
- 因为是base64编码的, 并非hash, 所以密码相当于明文的, 一般是配合https一起使用
- 浏览器一般需要对认证的header提供一个过期机制
- 服务器并不能提供登出功能,只能通过下面这种方法清掉缓存. However, there are a number of methods to clear cached credentials in certain web browsers. One of them is redirecting the user to a URL on the same domain containing credentials that are intentionally incorrect.
请求被转发路径
明白了上面这些, 需要实现起来就简单了.
先贴一个nginx配置示例
http { proxy_cache_path cache/ keys_zone=auth_cache:10m; upstream backend { server 127.0.0.1:9200; } server { listen 80; # Protected application location / { auth_request /auth-proxy; proxy_pass http://backend/; } location = /auth-proxy { internal; proxy_pass http://127.0.0.1:8080; proxy_pass_request_body off; proxy_set_header Content-Length ""; proxy_cache auth_cache; proxy_cache_valid 200 403 10m; } } }启动一个做ldap认证服务的daemon, 开在127.0.0.1:8080, 代码在https://github.com/childe/ldap-nginx-golang
- 用户请求/index.html的时候, 请求被转到 /auth-proxy/index.html (内部, 并非3XX, 对用户透明)
- /auth-proxy/index.html被我们的daemon处理.
- 因为第一次请求, 不会有Authorization header, daemon直接返回401, 并带上
WWW-Authenticate: Basic realm=""的header - nginx auth_request模块收到401返回码, 并把401返回给用户
- 浏览器收到请求, 弹出窗口, 让用户输入用户名密码
- 浏览器把用户名密码封装到header里面发送到服务器
- 还是转到/auth-proxy/index.html, 由daemon处理, 这次认证通过, 返回200
- nginx auth_request模块收到200返回码, 则把url转给http://backend/做处理.
- http://backend/ 是我们的ES restful服务, 该返回什么返回什么给用户了.
注:
- 如果用户密码在ldap认证不通过, 或者格式不对等等错误, 直接返回403给用户
- 每一个用户名/密码会被nginx缓存10分钟
- internal代表这是一个内部location, 用户直接访问 auth-proxy/ 会返回404
-
-
bash中将标准输出重定向到多处
echo "abcd" 1>f1 1>f2 1>f3, 我以为是后面的会覆盖前面的, 最后只是写到f3. 测试了一下居然不是, 就想了解一下到底发生了什么.
观察了一下, 发现单次重定向和上面这种多次重定向, 居然是不一样的实现.写一个简单的C程序, 做为输出源.
#include <unistd.h> #include <stdlib.h> int main(int args, char** argv) { int n = 8; char *buf = "abcdefg\n"; char *buf2 = "1234567\n"; write(STDOUT_FILENO, buf, n); write(STDERR_FILENO, buf2, n); sleep(100); exit(0); }最后sleep 100秒是为了方便观察fd情况.
单次重定向
./a.out >f1 2>f4然后看一下f1 f4都被哪个进程占用:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
a.out 22985 childe 1w REG 8,1 8 412766 f1
a.out 22985 childe 2w REG 8,1 8 412774 f4再看一下这个进程下的fd情况:
% ll /proc/23075/fd
total 0
lrwx—— 1 childe childe 64 6月 1 18:36 0 -> /dev/pts/10
l-wx—— 1 childe childe 64 6月 1 18:36 1 -> /tmp/m/f1
l-wx—— 1 childe childe 64 6月 1 18:36 2 -> /tmp/m/f4重定向多次
./a.out >f1 >f2 >f3 2>f4 2>f5查看一下结果, 其实是zsh帮忙用pipe做了中间介质, 才把a.out的输出写到了多个文件.
23226进程是我们的刚刚的C程序, 可以看到它并没有直接写到f1 f2 f3 f4 f5, 而是写到了两个pipe文件中.
而zsh读这2个pipe, 然后再分别写到f1 f2 f3 f4 f5
% lsof f1 f2 f3 f4 f5
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
zsh 23227 childe 11w REG 8,1 8 412766 f1
zsh 23227 childe 13w REG 8,1 8 412767 f2
zsh 23227 childe 15w REG 8,1 8 412769 f3
zsh 23228 childe 16w REG 8,1 8 412774 f4
zsh 23228 childe 17w REG 8,1 8 412775 f5% ll /proc/23226/fd
lrwx—— 1 childe childe 64 6月 1 18:37 0 -> /dev/pts/10
l-wx—— 1 childe childe 64 6月 1 18:37 1 -> pipe:[95495]
l-wx—— 1 childe childe 64 6月 1 18:37 2 -> pipe:[95496]% ll /proc/23227/fd
l-wx—— 1 childe childe 64 6月 1 18:37 11 -> /tmp/m/f1
l-wx—— 1 childe childe 64 6月 1 18:37 13 -> /tmp/m/f2
lr-x—— 1 childe childe 64 6月 1 18:37 14 -> pipe:[95495]
l-wx—— 1 childe childe 64 6月 1 18:37 15 -> /tmp/m/f3% ll /proc/23228/fd
l-wx—— 1 childe childe 64 6月 1 18:37 16 -> /tmp/m/f4
l-wx—— 1 childe childe 64 6月 1 18:37 17 -> /tmp/m/f5
lr-x—— 1 childe childe 64 6月 1 18:37 18 -> pipe:[95496] -
linux下读取磁盘时缓冲区大小如何影响性能
从每次read时的buffer size如何影响性能, 每次read时的buffer size如何影响性能2 总结来的. 这两篇都是一些当时的想法, 对的, 和错的. 现在总结一下.
这篇日志其实就是围绕Unix环境高级编程表3-2来讲的.
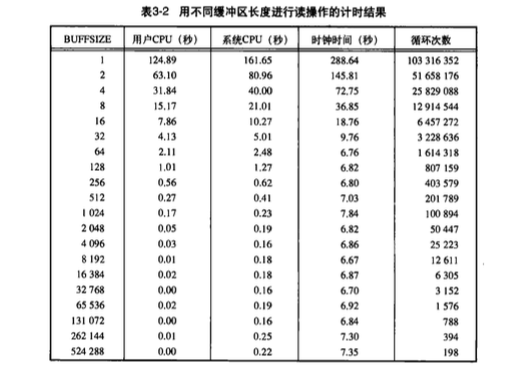
把我这边的测试结果记录一下, 后面会详细说明如何测试的. 数据大写是100M, 禁用readahead, 磁盘IO次数不精确, 因为上面还有别的应用在跑,仅供参考用.
buffsize 用户CPU(秒) 系统CPU(秒) 时钟时间(秒) 磁盘IO次数 IO时间 1 7.247 40.746 54.382 26962 6.362 2 3.665 19.393 28.608 26354 5.55 4 1.908 10.095 17.255 25906 5.252 8 1.000 5.879 11.857 25810 4.878 16 0.483 3.481 8.677 25985 4.713 32 0.283 2.195 7.067 25982 4.589 64 0.158 1.623 6.105 25711 128 0.094 1.414 5.920 25796 256 0.080 1.105 5.468 25794 512 0.057 1.057 5.278 25765 1024 0.049 0.821 4.988 25713 2048 0.054 0.898 5.045 25748 4096 0.040 0.854 5.124 25850 8192 0.033 0.919 4.970 25965 16394 0.017 0.898 5.164 25762 表格1: 不同buffer size下的cpu使用情况
readhead, 暂时先不管它, 后面再说
系统读取磁盘数据时, 会认为磁盘中接下来的连续数据也会很快被用到, 所以会预读取更多的数据, 这个叫做readahead.
我们先不考虑readhead, 后面再说. 为了消除readahead影响, 先把readahead设置为0.
blockdev --setra 0 /dev/sdablock size
blockdev --getbsz /dev/sda可以获取磁盘的block size大小.Linux系统读取文件时(不考虑readahead), 一次会从磁盘中读取block size大小的数据, 哪怕只是
read(fd, buf, 1), 也会从磁盘读取block size的数据.在我这个测试用的电脑上, block size是4096(bytes).
所以如果每次read(1)和每次read(4096), 虽然前者调用read的次数多了非常多倍, 但实际上磁盘IO次数是一样的. 因为循环次数特别多, 所以user cpu和sys cpu会多很多. 但用时钟时间减去前两者,实际使用的IO时间是差不多的.read(>4096)
如果调用read函数时, buffer size大于block size呢, 会不会进一步减少磁盘IO次数?
如果block size是4096, 我一个read(8192)调用, 会不会一次IO操作读取8192字节呢?
答案是不会的, 因为即使是一个文件, 存在磁盘的时候, 在物理结构上未必就是顺序存放的. 所以系统还是要一个个block size去读取, 然后再判断接下来应该读取哪一块block, 否则按照read的参数一次性读取很多, 很有可能是浪费的.readahead
前面说到, 系统读取磁盘数据时, 会认为磁盘中接下来的连续数据也会很快被用到, 所以会预读取更多的数据, 这个叫做readahead.
在有大量顺序读取磁盘的时候, readahead可以大幅提高性能. 但是大量读取碎片小文件的时候, 这个可能会造成浪费. 所以是不是调高还是看具体应用.
把readahead设置为256之后的测试结果, buffer size是1, 磁盘IO次数是922
real 0m43.212s user 0m6.715s sys 0m36.257s 922测试方法
- 用dd创建一个100M大小的文件
- 每次操作前, 先
echo 3 > /proc/sys/vm/drop_caches清一下, 这个不保证马上清掉, 最好sleep一下 - 记录操作前的磁盘IO次数
read1=$(cat /proc/diskstats | grep dm-0 | awk '{print $4}') - dd读取数据.
time dd if=testfile of=/dev/null ibs=$@ - 记录操作后的磁盘IO次数
read2=$(cat /proc/diskstats | grep dm-0 | awk '{print $4}')
关于/proc/diskstats的解释参考关于/proc/diskstats的解释
-
arp_ignore arp_announce解释
在利用LVS做redis集群中提到了arp_ignore arp_announce需要修改以配合LVS, 但当时没看明白这两个参数到底什么意思. 今天又找了些文章看, 并测试, 终于明白了一些.
arp_announce
还是先把英文的解释贴一下:
arp_announce - INTEGER
Define different restriction levels for announcing the local source IP address from IP packets in ARP requests sent on interface:
0 - (default) Use any local address, configured on any interface
1 - Try to avoid local addresses that are not in the target’s subnet for this interface. This mode is useful when target hosts reachable via this interface require the source IP address in ARP requests to be part of their logical network configured on the receiving interface. When we generate the request we will check all our subnets that include the target IP and will preserve the source address if it is from such subnet. If there is no such subnet we select source address according to the rules for level 2.
2 - Always use the best local address for this target. In this mode we ignore the source address in the IP packet and try to select local address that we prefer for talks with the target host. Such local address is selected by looking for primary IP addresses on all our subnets on the outgoing interface that include the target IP address. If no suitable local address is found we select the first local address we have on the outgoing interface or on all other interfaces, with the hope we will receive reply for our request and even sometimes no matter the source IP address we announce.The max value from conf/{all,interface}/arp_announce is used.
Increasing the restriction level gives more chance for receiving answer from the resolved target while decreasing the level announces more valid sender’s information.
这个是说, 一台机器在配置多个IP的时候, 发送arp请求报文时, 来源IP到底如何选择?
比如说我这机器有2个IP, 分别是172.16.4.132, 172.16.4.200. 在询问172.16.4.130 MAC地址的时候, 如何选择source ip呢?
如果172.16.4.132, 172.16.4.200还分别在2个网卡上呢?这是一条本机出去的arp request.
14:14:43.587157 ARP, Request who-has 172.16.4.130 tell 172.16.4.132, length 28可以看到这里选用了172.16.4.132做为source ip.
这里先宝义2个术语吧, 仅在本篇文章适用.
- source ip: arp request里面的, 如下面所提
- source address: ip包里面的, ip header里面的src ip address.
arp_announce就是提供了几种策略, 可以让系统更好的选择这个source ip.
arp_announce: 0
默认是0, 翻译出来就是, 配置在任意网卡上的任意IP地址. 还不是很明白如何选择, 测试的结果选择ip包里面的source address, 就是说如果接下来的IP包是用172.16.4.132做src ip, 就在arp request里面用172.16.4.132做srouce ip. 172.16.4.200也是一样.
测试如下:
两台机器,A(172.16.4.132, 172.16.4.200) B(172.16.4.130)A机器上面配置如下
eth0 Link encap:Ethernet HWaddr 00:0c:29:21:d7:58 inet addr:172.16.4.132 Bcast:172.16.4.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe21:d758/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:470177 errors:0 dropped:0 overruns:0 frame:0 TX packets:1682 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:479526719 (479.5 MB) TX bytes:169865 (169.8 KB) eth0:1 Link encap:Ethernet HWaddr 00:0c:29:21:d7:58 inet addr:172.16.4.200 Bcast:172.16.255.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1B机器上面配置如下
eth0 Link encap:Ethernet HWaddr 00:0c:29:c5:14:0f inet addr:172.16.4.130 Bcast:172.16.4.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fec5:140f/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:471838 errors:0 dropped:0 overruns:0 frame:0 TX packets:2517 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:481299703 (481.2 MB) TX bytes:250538 (250.5 KB)A机器上面,
nc -l 10000, 然后B机器nc 172.16.4.200 10000连过来. tcpdump抓包可以看到A机器上面的arp request请求如下:14:30:01.142332 ARP, Request who-has 172.16.4.130 tell 172.16.4.200, length 28如果B机器上面
nc 172.16.4.132 10000, A上面的arp request则是14:43:41.366599 ARP, Request who-has 172.16.4.130 tell 172.16.4.132, length 28arp_announce: 1
设置为1的话, source ip会避免选择不在一个子网的. 生成arp request的时候, 会遍历所有包括target ip的子网,如果source address在这个子网里面, 就会选用它做source ip. 如果没有找到这样的子网, 就应用level 2.
但我有一点没明白, 怎么判断source address在不在这个子网里面??
如果172.16.4.200的子网掩码是255.255.255.255, 我们看下测试结果.
255.255.255.0
子网掩码先不动, 还是255.255.255.0. 先把arp_announce置为1
# echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_announcearp缓存清一下
# arp -d 172.16.4.130B机器
nc 172.16.4.200 10000, 测试结果如下:14:54:47.174093 ARP, Request who-has 172.16.4.130 tell 172.16.4.200, length 28255.255.255.255
更改子网掩码为255.255.255.255, 然后再测试. arp request还是一样的.
A机器上面:
# arp -d 172.16.4.130 [root@virtual-machine:~] # ifconfig eth0:1 down [root@virtual-machine:~] # ifconfig eth0:1 172.16.4.200 netmask 255.255.255.255B机器
nc 172.16.4.200 10000, 测试结果如下:14:54:47.174093 ARP, Request who-has 172.16.4.130 tell 172.16.4.200, length 28arp_announce: 2
在这个级别下, 会忽略source address. 会在包含target ip的子网所在的网卡上寻找primary ip. 如果没有找到,就选择出口网卡(或者其他所有网卡)上面的第一个IP. 不管source address是什么, 而是尽可能的希望能收到arp reqeust的回复.
具体的测试过程就不罗列了, A上面有一个secondary ip 是 172.16.4.200/24, B运行
nc 172.16.4.200 10000的时候, A的arp request是17:39:30.975896 ARP, Request who-has 172.16.4.130 tell 172.16.4.132, length 28arp_ignore
arp_ignore - INTEGER
Define different modes for sending replies in response to received ARP requests that resolve local target IP addresses:
0 - (default): reply for any local target IP address, configured on any interface
1 - reply only if the target IP address is local address configured on the incoming interface
2 - reply only if the target IP address is local address configured on the incoming interface and both with the sender’s IP address are part from same subnet on this interface
3 - do not reply for local addresses configured with scope host, only resolutions for global and link addresses are replied
4-7 - reserved
8 - do not reply for all local addressesThe max value from conf/{all,interface}/arp_ignore is used when ARP request is received on the {interface}
这个相对来说, 就好理解多了.
如果机器A有两个IP 172.16.4.132,172.16.4.200. 当它收到一个arp request, 询问谁的ip是172.16.4.200时, 可以选择不回应. arp_ignore就是做这个控制的.
arp_ignore: 0
响应任何IP
arp_ignore: 1
如果请求的IP不在incoming interface, 不回应. (LVS DR模式里面就可以选择这个)
arp_ignore: 2
如果请求的IP不在incoming interface, 或者与来源IP不在一个子网, 不回应.
arp_ignore: 3
没看懂
arp_ignore: 4-7
保留值, 暂没用
arp_ignore: 8
不回应任何arp请求
-
lvs DR模式中, 为何一定需要一个virtual IP
在利用LVS做redis集群中记录了当时用LVS DR模式做redis高可用.
当时并没有多想, 为什么一定要给LVS一个VIP,而不能用他自己原有的IP.
今天又一次尝试时, 没有分配新的VIP, 而是用原有IP, 才发现这样是不行的.如果LVS所在机器IP是192.168.0.100, 两个real server是192.168.0.101/102.
两个real server上面需要在lo绑定192.168.0.100.
当LVS(192.168.0.100)做ARP询问192.168.0.101/102网卡地址的时候, 他们返回不到真正的192.168.0.100,因为这个IP地址也在自己的lo环路.
这就导致了192.168.0.100获取不到real server的MAC地址.用VIP情况就不一样了. 所有机器都绑定一个VIP 192.168.0.200. LVS询问ARP的时候, 请求应该是, 谁的IP是192.168.0.101, 请告诉192.168.0.100. 这样就可以顺序拿到real server的MAC地址了.