Journald Crash
昨天和芽哥一起查了一个 ETCD 切主的问题,挺有意思的,记录一下。
最终查明了根因,是使用 filebeat 采集 Journal 日志,引发 journald flush,导致高磁盘 IO,进而导致 ETCD 切主。
故障出现
ETCD 日志写到 systemd 里面。 芽哥要采集 ETCD 日志到 Clickhouse。我推荐了使用 filebeat。使用 docker-compose 启动,配置如下:
version: '2.3'
services:
filebeat:
image: beats/filebeat:8.2.0
container_name: filebeat
user: root
restart: always
dns_search: .
network_mode: host
environment:
ZONE: XXX
KAFKA_HOSTS: '["XXX"]'
volumes:
- /var/log/journal/:/var/log/journal/:z
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml
logging:
driver: "syslog"
options:
tag: filebeat
测试环境跑了几天没问题,就在生产上了一台ETCD服务器,结果启动 filebeat 之后几分钟,收到告警,etcd 切主了。简单排查下来,基本上确认了 IO 太高,导致 etcd 切主。
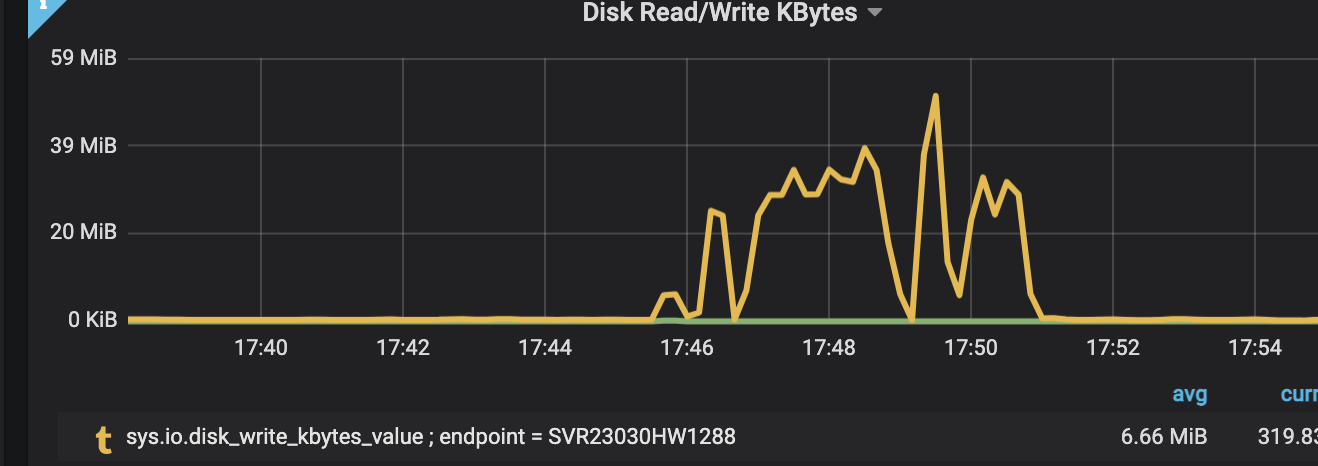
现在的问题是,IO 怎么这么高,谁导致的?
找到导致 IO 高的进程
还好,我们的 Hickwall 监控系统里面有一些当时的磁盘 IO 监控数据:
- 整个磁盘只有一个分区
- 当时是磁盘的写比较高,读正常
- Hickwall 还记录了当时 IO 写最高的进程是什么(时间线好像有点偏移?),经查是应该是 journald
陷入泥潭
当时现场的一些现象
芽哥看到故障之后,马上把 filebeat 停掉了。
芽哥提供了一些其他信息
-
另外几个跑了 filebeat 的 ETCD 机器,启动的时候也有磁盘小高峰,但只有不到1分钟,也没有导致切主。数据也正常采集。
-
故障的这台机器,filebeat 并没有采集到数据写入 Kafka
-
filebeat 17:46 启动,故障是 17:51 报出来的,17:51 停止 filebeat。
关于第一点,我也没有太多想法,暂且放一边,还是再看看故障的这台机器还有啥线索。
第二点,我去查了一下 filebeat 日志,看到是因为 kafka topic 不存在。这点我比较确定:是因为 kafka 集群配置了不自动创建topic,后面也被 kafka owner 确认了。 这个和磁盘高,想不到有什么因果关系。
芽哥又确认了一下 filebeat 会不会从头读所有日志,我看了一下配置,seek: tail,所以应该是不会的,而且是写磁盘高,不是读。
我这边看到的一些现象如下:
-
出问题是 17:50 左右,我看了 17:30 以来的 journald 记录的日志,并不多,只有 12927 条,KB 而已。
-
/var/log/journal/ 这个目录挂载进了 docker 容器,目录里面内容一共有 4GB。不确定大量磁盘写和这个挂载有没有关系?我当时猜测因为一些不可知的原因,数据被写到 /var/lib/docker/ 下面?不过简单测了下,正常情况下并不会。
-
/var/log/journal/ 下面的日志文件的时间有点奇怪,如下,全部都是 17:48 附近两分钟被写过。但不确定,是所有 4G 文件都是这两分钟写进来的,还是文件本来就有,只是这两分钟又写了一些数据进来。
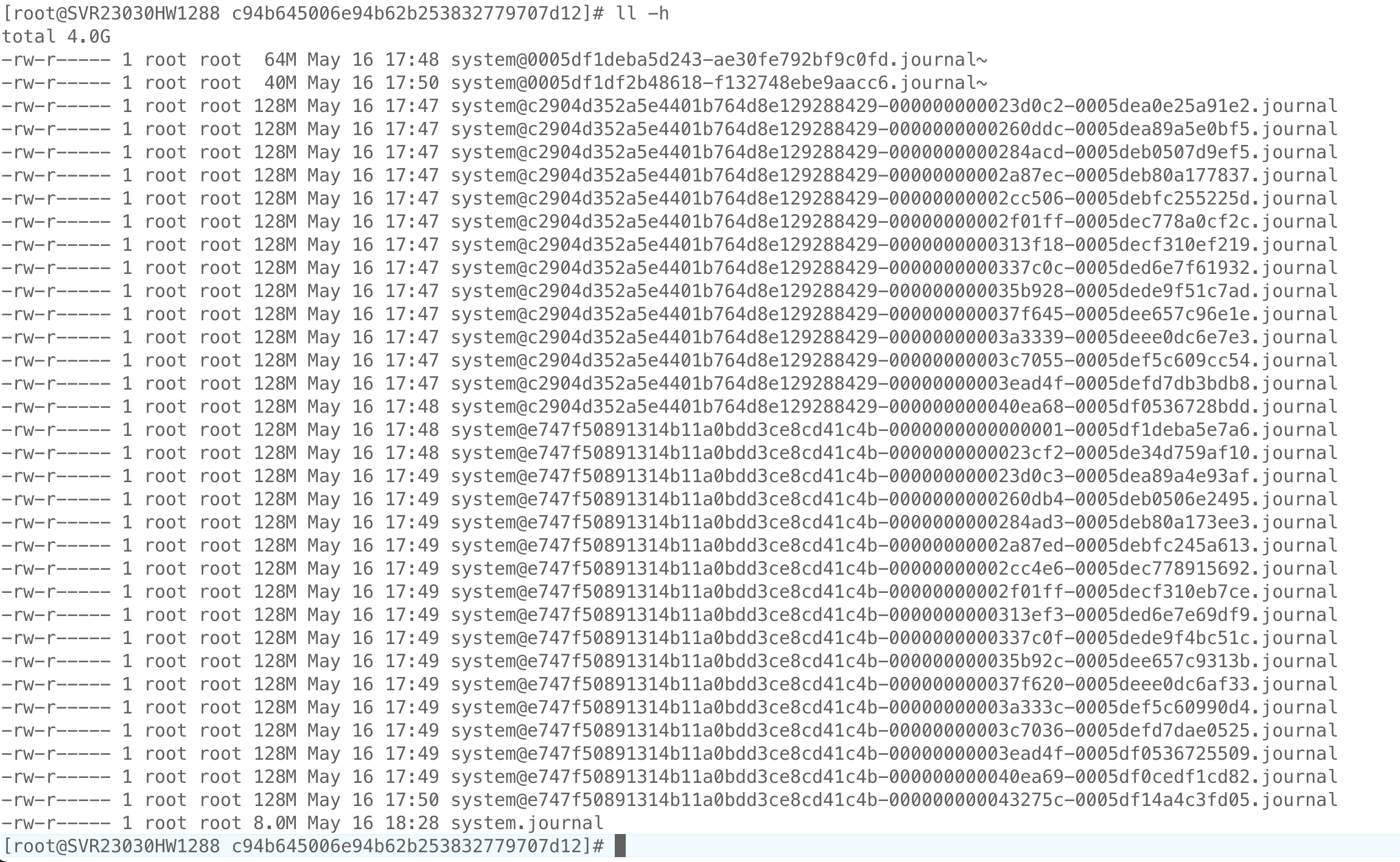
4G 数据从哪来
查看了一下 journald 应用自己的日志,不多,有这样两条:
May 16 17:46:13 SVR23030HW1288 systemd-journal[7212]: Permanent journal is using 8.0M (max allowed 4.0G, trying to leave 4.0G free of 195.8G available → current limit 4.0G).
May 16 17:48:04 SVR23030HW1288 systemd-journal[40397]: Permanent journal is using 3.8G (max allowed 4.0G, trying to leave 4.0G free of 192.0G available → current limit 4.0G).
两分钟之内写了近 4G 数据落盘。和整个现象还是比较符合的,但问题是,谁写了这么多日志进来呢?
我第一个怀疑的是 filebeat,毕竟正好他一启动,就出问题了。但是查下来,filebeat 产生的日志并不多。
所以我又怀疑了这个推断,
因为第一,前面已经提到,17:30 以来生成的日志也不多,
第二,journalctl --file system@c2904d352a5e4401b764d8e129288429-0000000000260ddc-0005dea89a5e0bf5.journal | less 看了一下日志文件中的内容,都是好久之前的日志了。
找了一个上面还没有使用 filebeat 采集日志的其他 ETCD 机器。
systemctl status systemd-journald 看到内存使用是 Memory: 4.1G。
我第一反应是,出故障的时候,是把内存数据刷到了磁盘上。问题是,为啥呢?难道平时数据都在内存中不落盘?又是什么触发的落盘呢?
又看了这个机器的 /var/log/journal,下面并没有数据,数据在 /run/log/journal/ 下面。
感觉是 filebeat 导致的,毕竟时间点就在一起。但是完全不知道 filebeat 怎么会导致 flush 数据。
怀疑上 journald 自身问题
journald 应用本身还有些这样的日志如下:
May 16 17:50:02 SVR23030HW1288 systemd-journal[600]: Permanent journal is using 3.9G (max allowed 4.0G, trying to leave 4.0G free of 191.1G available → current limit 4.0G).
May 16 17:50:02 SVR23030HW1288 systemd-journal[600]: Journal started
May 16 17:48:03 SVR23030HW1288 systemd[1]: systemd-journald.service watchdog timeout (limit 3min)!
芽哥说,“是不是因为 他挂了”。我当时的看法是“也可能是挂了导致,挂了肯定flush到磁盘”。但我们都不知道为啥这东西会挂掉。
我有点怀疑 filebeat, 有些还不知道的原因,导致 journal 挂了。但他应该不会直接和 journald 本身打交道,毕竟是容器里面的。交集还是目录挂载。
先不管,上网搜索一下看看,说不是 journald 有些 Bug。
…
搜索了约半小时,没查到什么有价值的东西。
确认是 journald 自己的问题
芽哥发来这样的日志,表示“正好赶上了这台 journal 有问题的时候启了 filebeat”。
[Mon May 16 17:42:32 2022] systemd-journald[40397]: File /var/log/journal/c94b645006e94b62b253832779707d12/system.journal corrupted or uncleanly shut down, renaming and replacing.
[Mon May 16 17:42:32 2022] systemd-journald[40397]: Failed to open runtime journal: Device or resource busy
[Mon May 16 17:42:36 2022] systemd-journald[40397]: Failed to create new runtime journal: No such file or directory
[Mon May 16 17:44:30 2022] systemd-journald[40397]: Assertion ‘f’ failed at src/journal/journal-file.c:132, function journal_file_close(). Aborting.
因为 filebeat 是 17:46 启动的(17:46:06才开始拉镜像),4分钟之前,journald 已经有问题了。
May 16 17:46:06 SVR23030HW1288 dockerd: time=”2022-05-16T17:46:06.716347578+08:00” level=debug msg=”Trying to pull beats/filebeat from https://MIRROR.com v2”
这么看起来,的确是冤枉 filebeat 了。
但我们两个又都觉得 “不会。。这么巧吧~?”。但不管怎么巧,证据就在眼前,的确是冤枉 filebeat 了。
我自己又补充:“而且filebeat前面应该是读到日志了,否则也不会发Kafka吧”。
峰回路转
4 分钟之后。。。
我发现 journal 看到的 journald 应用自身的日志,时间戳和前面芽哥发我的不一样。
我这边看到的一些日志如下:
[root@SVR23030HW1288 ~]# journalctl -k | grep jour
May 16 17:50:02 SVR23030HW1288 systemd-journald[40397]: File /var/log/journal/c94b645006e94b62b253832779707d12/system.journal corrupted or uncleanly shut down, renaming and replacing.
May 16 17:50:02 SVR23030HW1288 systemd-journald[40397]: Failed to open runtime journal: Device or resource busy
May 16 17:50:02 SVR23030HW1288 systemd-journald[40397]: Failed to create new runtime journal: No such file or directory
May 16 17:50:02 SVR23030HW1288 systemd-journald[40397]: Assertion 'f' failed at src/journal/journal-file.c:132, function journal_file_close(). Aborting.
和芽哥确认了一下,他是使用 dmesg 看到的日志。
我自己倾向于 journal 时间戳不准。因为
第一,dmesg 看到的这几条日志之间是有些时间差的。journal 的全部是同一秒。
第二,journal 本身已经有问题了,可能是 IO 导致之前的日志全部堆积在这一秒才写下?
10 分钟之后。。。
确认了 demsg 日志是不准确的,测试如下:
[root@SVR23030HW1288 filebeat]# echo TEST > /dev/kmsg
[root@SVR23030HW1288 filebeat]# dmesg -T | tail -1
[Mon May 16 23:25:47 2022] TEST
所以,fileebat 还是最大嫌疑。
问题核心
再次梳理一下,应该还是 journal 日志 flush 到磁盘导致的。此时又多了一个小小的佐证,看 Hickwall 监控,磁盘正好减少了4G。
问题是,为什么 flush ?
我开始网上搜索以及翻阅 man 手册,想看一下什么情况下会触发 flush 。
对比看了一下故障机器和非故障机器的 /etc/systemd/journald.conf 配置,并对照 man journald.conf 查看哪个参数决定了 flush 。
期间芽哥发来了 Storage 这个参数的解释,不过后面还跟了不少其他内容,我给忽略掉了。。
Storage= 在哪里存储日志文件: “volatile” 表示仅保存在内存中, 也就是仅保存在 /run/log/journal 目录中(将会被自动按需创建)。 “persistent” 表示优先保存在磁盘上, 也就优先保存在 /var/log/journal 目录中(将会被自动按需创建), 但若失败(例如在系统启动早期”/var”尚未挂载), 则转而保存在 /run/log/journal 目录中(将会被自动按需创建)。 “auto”(默认值) 与 “persistent” 类似, 但不自动创建 /var/log/journal 目录, 因此可以根据该目录的存在与否决定日志的保存位置。 “none” 表示不保存任何日志(直接丢弃所有收集到的日志), 但日志转发(见下文)不受影响。 默认值是 “auto”
夜里 00:09 了,我不经意间提了一个现象:“出问题的是Auto, 我看了一下, /var/log/journal 好像就是一直没创建,直到今天下午5点多”。
芽哥马上回我,“那就是 挂载的时候创建饿了” “然后写进去了。。。”
我这时候才反应过来,man 手册里面的 Storage 解释是啥意思。我看的机器上面的 man page 是英文的,英语太差,没怎么看明白。发出来看一下:
Storage= Controls where to store journal data. One of “volatile”, “persistent”, “auto” and “none”. If “volatile”, journal log data will be stored only in memory, i.e. below the /run/log/journal hierarchy (which is created if needed). If “persistent”, data will be stored preferably on disk, i.e. below the /var/log/journal hierarchy (which is created if needed), with a fallback to /run/log/journal (which is created if needed), during early boot and if the disk is not writable. “auto” is similar to “persistent” but the directory /var/log/journal is not created if needed, so that its existence controls where log data goes. “none” turns off all storage, all log data received will be dropped. Forwarding to other targets, such as the console, the kernel log buffer, or a syslog socket will still work however. Defaults to “auto”.
“auto” is similar to “persistent” but the directory /var/log/journal is not created if needed, so that its existence controls where log data goes.
看到到这里的时候, its existence 没理解 ,不知道是指的啥。
终于懂了,原来就是 /var/log/journal 目录不存在,Auto 就不会落数据到这里,直到这个目录创建。
到是第一次见到有这么玩的。以前遇到的都是,启动的时候检查,如果有目录就写,没目录就自动创建或者是报错。还没见过运行期间随时检查的。
后记
问题到这里已经解决了。但其实到最后我还是没查清楚,什么时候会写数据到磁盘,后面才看到 SyncIntervalSec 参数。默认 5分钟刷新一下,但CRIT, ALERT or EMERG 级别的日志会马上落地以防丢失。